What’s on the Menu?, New York Public Library (ed.), 2011–2024. https://menus.nypl.org/ (Last Accessed: 14.03.2025). Reviewed by ![]() Janosch Förster (SLUB Dresden), Janosch.Foerster@slub-dresden.de. ||
Janosch Förster (SLUB Dresden), Janosch.Foerster@slub-dresden.de. ||
Abstract:
In 2011, the New York Public Library began indexing a portion of its menu card collection from the Buttolph Collection through a crowdsourcing project. The goal of the project, What’s on the Menu, was to record the dishes and prices on the digitized items in addition to the metadata provided by the library. The participation process was designed to be as low-threshold and simple as possible. The review scrutinizes the aims, approaches and deficiencies of the project, which unfortunately was discontinued in 2016.
Speise- und Menükarten und ihr wissenschaftliches Potenzial
2Zunächst sei zum besseren Verständnis des Projekts kurz erläutert, um welche Objekte es genau ging und warum es sinnvoll ist, in eine Tiefenerschließung via Crowdsourcing zu investieren. Der englische Begriff menu umfasst sowohl Speise- als auch Menükarten und ist damit weniger trennscharf als die begriffliche Differenzierung im Deutschen.4 Hierzulande bezeichnet eine Menükarte eine kulinarische Gebrauchsschrift, die eine festgelegte Abfolge von Speisen für ein singuläres kulinarisches Ereignis enthält. Eine Speisekarte dokumentiert das gesamte Angebot eines Restaurants, in der Regel mit Preisen versehen, aus dem eine oder mehrere Speisen ausgewählt werden können. Eine Speisekarte ist über einen längeren Zeitraum gültig (es sei denn, es handelt sich um eine Tageskarte). Im Projekt What’s on the menu wurden beide Idealtypen und auch sämtliche Mischformen als eine Gattung von Ephemera behandelt. Streng genommen müsste man beide Objektarten, Speisekarten und Menükarten, aufgrund ihrer erheblichen strukturellen Unterschiede auch verschiedenartig behandeln und ggf. die Metadatenerfassung und Erschließungslogik differenziert angehen. Da es aber bisher gar keine etablierten Metadatenstandards für Menü- und Speisekarten gibt, hat die NYPL ihre eigene Standards definiert, so wie es andere Menükartensammlungen weltweit ebenfalls tun.5
3Speisekarten informieren über das taxierte Speise- und Getränkeangebot eines Lokals zu einer bestimmten (aber retrospektiv nicht immer eindeutig zu bestimmenden) Zeit. Dabei lassen sich oftmals nicht nur Aussagen über die benannten Gerichte (z. B. „Pfirsich Melba“, „Ratatouille“), ihre Zubereitung (gegrillt, flambiert, gekocht), sondern auch die dafür verwandten Naturprodukte (z. B. Hummer, Trüffel oder schlicht Äpfel) oder spezifische Marken, Hersteller und Produktbezeichnungen („Coca Cola“, „Piesporter Michelsberg, J & H Selbach, 1999 (Mosel)“) treffen. Im Projekt wurden alle kulinarischen Einträge auf der Speisekarte global als „Dishes“ erfasst, eine weitere Differenzierung fand nicht statt, worauf noch zurückzukommen ist. Auch Menükarten benennen verschiedene Gerichte oder Produkte, hierbei jedoch in einer für das Objekt der Menükarte wesentlichen, genau festgelegten Reihenfolge und oftmals mit korrespondierender Weinbegleitung. Mitunter werden nicht nur Ort und Zeit, sondern auch beteiligte Akteure, etwa wichtige Gäste, der oder die Köche (sehr selten auch Köchinnen), begleitendes Musik- oder Kulturprogramm usw. vermerkt. Diese Begleitinformationen wurden im Projekt nicht strukturiert erfasst.
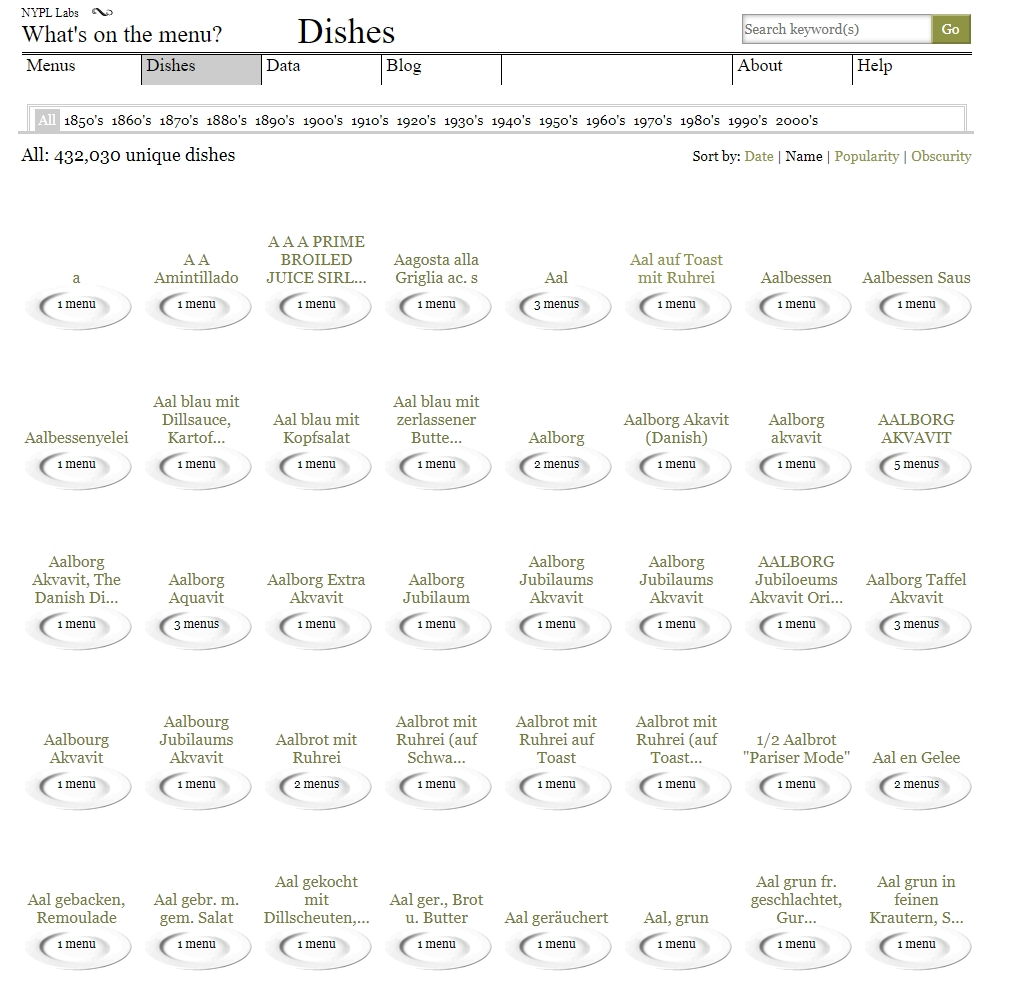
4Für die Wissenschaft sind Informationen auf Menü- und Speisekarten von großem Interesse, denn sie erlauben eine breite statistische oder quantitative Analyse ebenso wie eine tiefgehende qualitative Beschäftigung mit vergangener Esskultur. Um die Daten aber disparat zu halten und Vergleiche auch über Epochen- und Sprachgrenzen hinweg zu gewährleisten, wäre es nötig, die erfassten Daten, also die Gerichte, Produkte, Orte usw. zu normalisieren, sie also mit Normdatenbanken abzugleichen oder zumindest ein kontrolliertes Vokabular im Hintergrund zu installieren, in dem eindeutige Entitäten definiert wurden, denen die erfassten Zeichenketten dann zugeordnet werden können. Um den Erfassungsprozess der Daten durch Nutzerinnen und Nutzer aber so einfach wie möglich zu halten, wurde im Projekt What’s on the menu darauf verzichtet. Demensprechend entstanden beispielsweise 14 Einträge für dasselbe Produkt, den Digestif „Aalborg Akvavit“, darunter mindestens zwei Einträge, die schlicht auf Rechtschreibfehlern basieren („Akavit“). Auch für Geflügelsalat („chicken salad“) finden sich über 20 verschiedene Schreibweisen, deutsche oder französische Übersetzungen noch nicht mitgerechnet. Sie verweisen alle auf das mehr- oder weniger selbe Produkt oder Gericht, bilden aber Dutzende Datenobjekte und somit lässt sich eben nicht reliabel nachweisen, wann Geflügelsalat erstmals oder wo er wie oft serviert wurde. Die Angabe von rund 1,3 Millionen im Projekt erfassten „dishes“ ist ebenfalls irreführend, zumal auf der Unterseite Dishes nur noch 430.000 „unique dishes“ erwähnt werden, ohne das klar wird, wie es zu der Reduktion kommt.
Praxis der Datenerfassung durch die Crowd
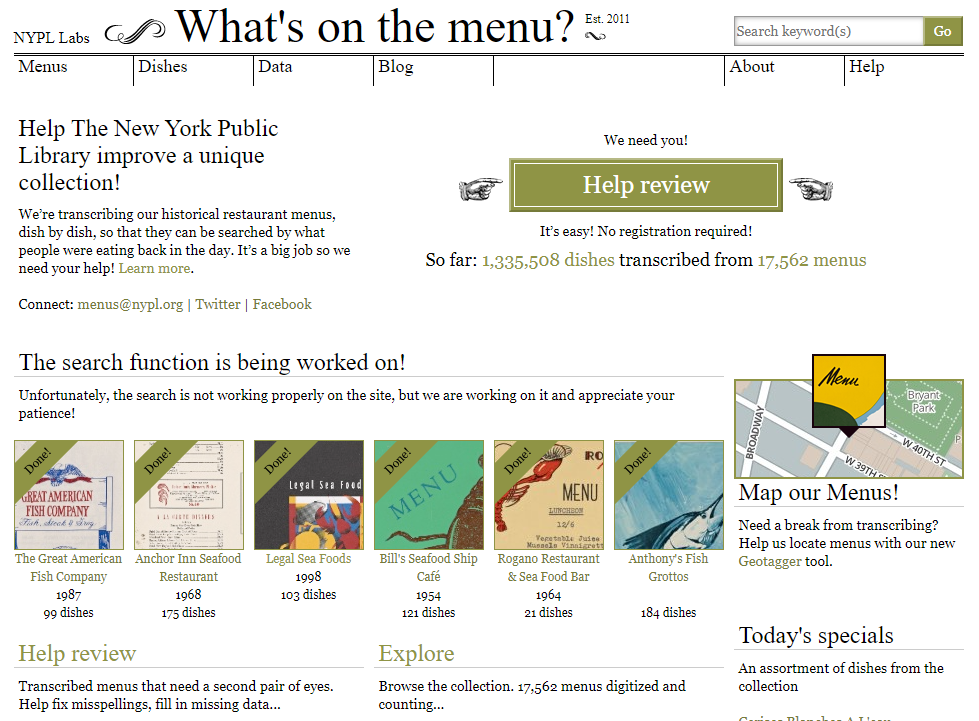
6Während in der Logik der Tiefenerschließung einige Defizite erkennbar sind, war die propagierte Methodik des Projekts der NYPL, nämlich die niedrigschwellige Einbindung von Bürgerwissenschaftlerinnen und –wissenschaftlern, ohne Frage effektiv. Nach einiger Vorbereitung wurde die Beta-Version der Website am 18. April 2011 über den Twitter-Account der Bibliothek bekannt gemacht.6 Bereits zehn Tage später waren 100.000 Gerichte erfasst worden (Lascarides und Vershow 2014, 123). Die Medien, unter anderem die New York Times, berichteten unmittelbar danach (New York Times, 2011) und auch einige Köche wie Mario Batali oder Doug Crowell begrüßten das Projekt namentlich oder kochten Speisen von den erfassten Menükarten nach.
7Wie war eine solch fulminanter Start des Projekts möglich? Vermutlich lag dies vor allem an der maximal niedrigschwelligen Beteiligungsmöglichkeit. Während des aktiven Betriebs der Website war es für alle Nutzenden weltweit möglich, ohne jegliche Anmeldung, Autorisierung oder Qualifikation, ein neues Menü- oder Speisekartendigitalisat vorgelegt zu bekommen und mit der Erfassung der Gerichte auf dem Dokument zu beginnen. Die technische Umsetzung hierzu war denkbar einfach: Per Mausklick wurden die ungefähren Koordinaten des Beginns jedes Textbausteins erfasst. Diesem Datenpunkt (dish marker) konnte nun in drei Stufen ein unterschiedlich langer Abschnitt auf dem digitalen Abbild der Menükarte zugewiesen werden, um zumindest grob eine Schätzung der Dimension des zu erfassenden Schriftzugs festzuhalten. Der eingegebene Text konnte mit der Angabe „This is my best guess (text is not 100% readable)“ als fraglich markiert werden. Nach der so erfolgten freien Transkription einer Menükarte erhielt diese den Status „Review“. Richtlinien oder Konventionen zur Transkription wurden, bis auf die im oben erwähnten Help-Bereich angegebenen, nicht festgelegt. Andere Nutzerinnen und Nutzer konnten nun die bereits einmal erfassten Annotationsdaten verifizieren, ändern oder löschen. Während der Bearbeitung erhielt die Menükarte einen Indikator, der erkennen ließ, dass dieses Digitalisat gerade bearbeitet wurde, um Datenkorruption oder unbeabsichtigte Löschung zu vermeiden. Anschließend erhielt die Menükarte den Status „Done“ und die erhobenen Daten wurden in der Datenbank freigeschaltet, indexiert und in den Abfragebereich der Suchmaschine des Portals übernommen. Zunächst sollte durch die Nutzenden auch der Preis des Gerichts, die Währung und die Position des Gerichts innerhalb der Struktur der Menü- oder Speisekarte (z. B. Vorspeise, Dessert oder Getränkekarte) erfasst werden. Dies erwies sich aber als extrem repetitiv und damit ermüdend. Daher wurde die Währung durch Bibliothekspersonal manuell vorerfasst und der Versuch der Verarbeitung der Objektstruktur aufgegeben. Lediglich der Herkunftsort der Objekte ließ sich in einer späteren Version der Website per Geotagger-Tool lokalisieren und zusätzlich erfassen. Leider ist diese Funktion inzwischen vom Netz genommen, so dass sich über die Durchführung dieses Teilprojekts kaum noch etwas sagen lässt.
8Trotz des erheblichen Anteils an öffentlicher Beteiligung blieb für die Mitarbeiterinnen und Mitarbeiter der Bibliothek ein beträchtlicher Arbeitsaufwand. Denn bevor die Menükarten in den Crowdsourcing-Prozess eingespeist werden konnten, mussten die grundlegenden Metadaten für die Karte erfasst werden. Ausgewählt wurden die Eigenschaften Veranstaltungsort (Location), Anzahl der Gerichte, Datum (Date), Veranstalter (Sponsor), Ort (Place), Beschreibung (Physical description), eine Identifikatiosnummer (Call number) und Bemerkungen (Notes). All diese Metadaten wurden, soweit sich das rekonstruieren lässt, als Zeichenkette erfasst. Eine Ausnahme bildete möglicherweise die Zahl der Gerichte. Veranstaltungsdaten wurden in amerikanischer Schreibweise erfasst (MMM TT, JJJJ), falls ein genauer Tag nicht ermittelbar war, enthielt die Zeile nur ein Jahr oder eine andere Angabe. Die Metadaten wurden genauso wie die Annotationsdaten weder normalisiert noch verknüpft. Ob zumindest gezielt in den Volltexten der Metadaten gesucht werden konnte, lässt sich nicht mehr rekonstruieren. In jedem Fall wäre eine Suche schwierig und inkonsistent gewesen, denn die fehlende Normalisierung hätte, wie bei den Gerichten, zu zahlreichen falsch-positiven und falsch-negativen Treffern geführt. Selbst für die physische Beschreibung scheint es keine Konvention gegeben zu haben. Hier finden sich Angaben in Zentimetern, in Zoll, mit Komma, ohne Komma, mit zusätzlicher Beschreibung („Folder, Illustrations“) oder nicht mehr zuzuordnenden Abkürzungen. Vollkommen frei scheint das Feld Bemerkungen/Notes gewesen zu sein. Hier finden sich teilweise Zitate aus dem Objekt (zum Beispiel werbende Claims), andernfalls Kommentare („handwritten, many flags“) oder Provenienzinformationen, oftmals aber auch dann kein Eintrag, auch wenn ein solcher vielleicht nützlich gewesen wäre. Wer diese Metadaten wann erfasst hat, lässt sich mit den im Frontend zur Verfügung gestellten Daten nicht mehr rekonstruieren. Fest steht, dass diese Daten nicht von der Community erfasst wurden und auch nicht erfasst werden sollten. Neben der Normalisierung bedarf es bei ähnlichen Projekten also auch einer deutlich präziseren Anleitung sowohl für das professionelle Bibliothekspersonal als auch für die Bürgerwissenschaftlerinnen und –wissenschaftler.
9Die Niedrigschwelligkeit des Crowdsourcing-Prozesses erwies sich bei „What’s on the menu“ als Segen und als Fluch. Zwar konnten bis Ende 2014 laut den offiziellen Angaben 17.545 Menükarten mit angeblich 1,3 Mio. Gerichten erschlossen werden. Nicht erfasst wurden aber die Kontaktdaten der mitunter sehr fleißigen Helferinnen und Helfer, die diese beeindruckende Leistung in kürzester Zeit erbracht hatten. Die Projektverantwortlichen konnten mit ihrer Community ausschließlich diffus und indirekt über die sozialen Netzwerke (konkret Facebook und Twitter) kommunizieren. Die zweite Möglichkeit bestand darin, die Beteiligten per E-Mail-Newsletter und nur dann zu informieren, wenn diese zuvor per Kontaktformular freiwillig und proaktiv ihre E-Mail-Adresse hinterlassen hatten, was wohl nur die wenigsten tatsächlich getan haben dürften. Die Frage, ob den Freiwilligen Rechte an der von ihnen erbrachten Leistung zukämen, wurde durch die fehlende Verbindung ebenfalls recht brachial ‚geklärt‘: Wer anonym an einem Crowdsourcing-Projekt teilnehme, wer also schon direkt nach der Dateneingabe nicht mehr fassbar ist, dem könne auch keine Teilhabe an den geschaffenen Werten eingeräumt werden, so die Verantwortlichen (Lascarides und Vershow 2014, 122). Genauso wenig war es möglich, besonders verdiente Teilnehmende im Crowdsourcing-Projekt zu identifizieren und zu belohnen oder wenigstens ihre Mitwirkung öffentlich wertzuschätzen. Der euphorische Impuls der ersten Wochen und Monate konnte so wohl keine ausreichend langfristige Wirkung entfalten. Die für 2015 geplante Einführung eines Login-Bereichs wurde nicht mehr realisiert. Die Autoren des zitierten Zwischenberichts gaben sich dementsprechend lernfähig. In einem Absatz mit dem Untertitel „Lessons learned“ gaben sie einige wertvolle Tipps für zukünftige Projekte. Neben der niedrigschwelligen Beteiligung, der einfachen Bedienung und der emotionalen Ansprache in der das Projekt „What’s on the menu“ ohne Frage reüssierte, stellten sie auch fest, es sei unumgänglich für Crowdsourcing-Projekte, Belohnungen zu verteilen („give rewards“) und eine Community aufzubauen („build a community“, Lascarides und Vershow 2014, 134-135).
10Es ließ sich leider nicht klären, warum die Unterstützung für das Projekt 2016 offenbar völlig überraschend zurückgezogen wurde. Mit dem plötzlichen Ende wurde auch der Zugriff auf die Daten weitgehend eingestellt. Inzwischen sind die Digitalisate wie erwähnt nur noch über die digitalen Sammlungen der New York Public Library erreichbar.7 Die angekündigte öffentliche API ist nicht mehr ansprechbar, das GitHub Repository wird seit 2014 nicht mehr gepflegt, lässt aber immerhin noch Rückschlüsse auf die API Response zu.8
Fazit
11Zusammenfassend fällt das Urteil über das Projekt What’s on the menu gemischt aus. Während das Crowdsourcing an sich auf der einfach, intuitiv und sinnlich ansprechend gestalteten Website in kurzer Zeit zu beeindruckenden Ergebnissen führte, eine große Aufmerksamkeit für das Medium Menükarte generiert wurde und einige Ansätze bei der Datenerfassung durchaus Vorbild sein können, müssen auf der konzeptionell-inhaltlichen Ebene erhebliche Defizite konstatiert werden. Die Daten aus What’s on the menu sind nicht nur deswegen nicht mehr nutzbar, weil das Projekt offenbar ohne ausreichende Finanzierung geplant war und nun nicht mehr erreichbar ist, sondern auch, weil an den Bedarfen der Wissenschaft, die zwingend auf die Normalisierung der Daten und damit eine strukturierte und verlässliche Suche angewiesen ist, vorbei und recht hemdsärmelig vorgegangen wurde. Es bleibt zu hoffen, dass die erhobenen Daten (darunter die Digitalisate der Menükarten selbst, die heute nicht mehr abrufbar sind) so gespeichert wurden, dass sie in einem zukünftigen Projekt, vielleicht mithilfe maschinellen Lernens, noch einmal umfangreich aufgearbeitet werden können und damit der Beitrag der vielen Bürgerwissenschaftlerinnen und -wissenschaftler, die an diesem Projekt beteiligt waren, nicht umsonst war.
12Ein zukünftiges Projekt sollte die oben festgestellten Defizite vermeiden. Erfasste Daten sollten mithilfe von Normdaten oder einem kontrollierten Vokabular erschlossen werden. Dies könnte auch den Prozess der Erfassung vereinfachen, auch wenn die Orthografie des Originals beibehalten werden sollte. Zudem sollte die Mitarbeit nur nach Angabe eines Kontakts, wenigstens einer E-Mail-Adresse möglich sein, um die Helferinnen und Helfer identifizieren, direkt ansprechen und auch ihre Arbeit angemessen würdigen zu können. Darüber hinaus ist nach über zehn Jahren zu vermuten, dass moderne Verfahren maschinellen Lernens bei der Erfassung und Verarbeitung der Daten die manuelle Arbeit deutlich reduzieren bzw. erleichtern würden. Ganz ohne die Hilfe menschlicher Intelligenz werden aber so komplexe und diverse Objekte wie Menükarten, nicht zu erschließen sein. In jedem Fall braucht es deshalb sowohl für die Daten als auch für die beteiligte Crowd einer aktiven, langfristigen Pflege, damit die Ergebnisse des Projekts nicht auf der Strecke bleiben.
Anmerkungen
[1] Website: https://menus.nypl.org/.
[2] Geboren als Frances Editha Buttles, 1844–1924.
[3] https://digitalcollections.nypl.org/collections/the-buttolph-collection-of-menus.
[4] Vgl. den Eintrag im Oxford English Dictionary, das unter dem Lemma ‚menu‘ folgende Aufzählung angibt: „A list of the dishes to be served at a meal, or which are available in a restaurant, etc.; a card on which such a list is written or printed, a bill of fare. Also: the food available or to be served at a meal or in a restaurant.“ (https://www.oed.com/dictionary/menu_n?tab=meaning_and_use#37279961).
[5] Verwiesen sei an dieser Stelle exemplarisch auf die Sammlungen des Culinary Institute of America (http://ciadigitalcollections.culinary.edu/digital/collection/p16940coll1), der University Library Las Vegas (https://special.library.unlv.edu/collections/menus), der Stadtbibliothek Dijon (http://patrimoine.bm-dijon.fr/pleade/subset.html?name=sub-menus) oder die Menükartensammlung der Bibliotheque Publique et Universitaire de Neuchatel in der Schweiz (http://bpun.unine.ch/menus) sowie der Staatsbibliothek Berlin (https://staatsbibliothek-berlin.de/die-staatsbibliothek/abteilungen/handschriften-und-historische-drucke/sammlungen/graphische-sammlungen/menuekarten). Große, aber bisher nicht vollständig erschlossene Menükartensammlungen besitzen zudem der Verein Deutsche Tafelkultur e. V. in Frankfurt (https://www.tafelkultur.com/verein-stiftung/sammlungen) sowie das Deutsche Archiv der Kulinarik an der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek Dresden (https://www.slub-dresden.de/entdecken/deutsches-archiv-der-kulinarik).
[6] https://x.com/nypl_menus/status/60091735388340224 [aktuell nicht archivierbar].
[7] https://digitalcollections.nypl.org/collections/the-buttolph-collection-of-menus.
Bibliographie
Cardiel, Mateo Sancho. 2023. „New York Public Library houses a captivating und undiscovered archive of over 45,000 food menus.“ El Pais, 22. Juli 2023.
Lascarides, Michael, Ben Vershbow. 2014. “What’s on the menu?: Crowdsourcing at the New York Public Library.“ In Crowdsourcing our Cultural Heritage, edited by Mia Ridge, 113–138. Farnham: Ashgate.
New York Times. 2011. “The Library Hands Out Menus to Thousands of Volunteers”, New York Times, 26. April. https://archive.nytimes.com/dinersjournal.blogs.nytimes.com/2011/04/26/the-library-hands-out-menus-to-thousands-of-volunteers/.