Classical Latin Texts. A Resource Prepared by The Packard Humanities Institute (PHI), Packard Humanities Institute (ed.), 2015. http://latin.packhum.org/ (Last Accessed: 31.01.2018). Reviewed by Dániel Kozák (Eötvös Loránd University, Dept. of Latin), kozak.daniel (at) btk.elte.hu. ||
Abstract
PHI Latin Texts (PHI, in short), although published online in 2015, provides access to the contents of the 1998 CD-ROM version of the same database. It has a minimalistic user interface which allows users to browse the collection and run full-text searches on selected works or the whole collection. The texts are taken from reliable critical editions, but without introduction and critical apparatus. Although technologically obsolete by today’s standards (e. g. TEI/XML are not used), PHI is still one of the most widely used open access text collections of Roman literature.
Review
1With the emergence of computers, classical philologists had quickly recognized the enormous value a consistently encoded digital corpus of ancient Greek and Latin texts would offer for them. Two databases of similar design were the result of work started already in the 1970’s: Thesaurus Linguae Graecae (TLG), containing ancient Greek texts, and the Packard Humanities Institute database of ancient Latin texts (henceforth, PHI).1 Up to the end of the 1990’s, subsequent versions of these databases were distributed on CD-ROM, to be accessed with various free and commercial applications available for different platforms.2
2In the early 2000’s, however, the paths of TLG and PHI separated. TLG was made available online in 2001, with a full version by subscription and a limited set of texts for free.3 It is constantly updated with the addition of more texts and new search options. PHI, on the other hand, had remained for another decade in the offline world, with no new versions of the database produced (the latest being version 5.3, published in 1991). Finally, in 2015, the latest version of PHI was made freely accessible online.4 The online version specifically is the subject of this review, written from the perspective of a classical philologist rather than that of an expert in digital humanities.5
3I cannot offer a comprehensive comparison of all currently available databases containing ancient Latin texts; but I will compare some features offered by PHI with free databases such as Perseus Digital Library (henceforth, PDL) or The Latin Library (LL), and paid databases such as Brepols’ Library of Latin Texts (LLT) or De Gruyter’s Bibliotheca Teubneriana Latina Online (BTL).6
4Although there is no general documentation (apart from three sentences on the ‘About PHI Latin’ page),7 the above outlined history makes it clear that PHI has always been a research tool designed primarily for professional classicists. The online version contains nearly all surviving literary texts (‘literary’ in the broad sense of having been written for public circulation), including not just complete works, but also fragments (in many cases, only a couple of words) from the beginnings of Latin literature in the 3rd century BC up to AD 200 (concerning the editions used, see below). A few late antique texts, however, are also present, such as Servius’ (4–5th c.) commentaries on Vergil. In all, 836 works by 362 authors are represented. PHI does not (and was to my knowledge never intended to) contain texts from inscriptions and papyri (except for a few literary works not known otherwise, such as Augustus’ Res gestae). The only difference between the coverage of texts in the online PHI and the latest CD-ROM version is that the latter also contains several (not just Latin) versions of the Bible and John Milton’s Paradise Lost and Defensio pro populo Anglicano (First Defence). Actually, the removal of these texts made the online PHI a more uniform textual corpus with regard to language and period.
5The limit of AD 200, of course, remains arbitrary, and the addition of just a few later texts such as Claudian’s epic De raptu Proserpinae or Ammianus Marcellinus’ Res gestae covering later Roman history (both 4th c. works) would have improved the coverage of the respective genres of (non-Christian) Roman literature considerably. Nevertheless, the virtually complete coverage of literary texts for the selected period is remarkable, and makes PHI (to my knowledge) the only freely available database allowing representative and reliable corpus-wide searches for that much of surviving Roman literature. To include late antique texts in the research, one either has to use paid databases with greater period coverage (such as LLT and BTL), or consult individual texts in other free databases (Ammianus and Claudian, for example, are both included in PDL and LL).8
6Another strength of PHI, when compared to other free databases of similar nature, is that its texts are based on high-quality transcriptions from reliable and, if possible, recent critical editions available at the time of building the database. (By comparison, PDL offers reliably transcribed texts from earlier, out of copyright editions; LL offers texts which are sometimes transcribed with many typos, often from obsolete, unreliable or unidentified editions.) Only the established text itself is included in PHI; introduction, apparatus criticus and any additional material must still be consulted in the print editions themselves.
7The only – but crucially important – kind of metadata or annotation accompanying the texts themselves are the standard numeric markers which are used in classical philology for consistent and (mostly) edition-independent citation of even short passages (e.g. 23.45.4.2 referring to a given book/chapter/sub-chapter/line in a lengthy prose work such as Livy’s monumental history of Rome, Ab Urbe Condita). PHI can also handle URL’s containing such references.9 This URL scheme, however, is undocumented and unfortunately not employed by PHI when navigating through the user interface; still, it allows other LOD-services like the Classical Works Knowledge Base10 (a parser for such standard citations) to include links to PHI alongside other databases.
8Texts can be displayed in Unicode (the default) or Beta code11 (designed during the 1980’s to allow precise encoding of Ancient Greek, originally, but used in both TLG and PHI). It is not stated in which format the texts are stored; but it seems more probable that it is (some derivation of) the original format used on the PHI CD-ROM rather than TEI/XML (the use of the latter is one of the strengths of PDL).
9The CD-ROM version of PHI (and TLG) contains only the database itself. The online version, by contrast, is tied to its own user interface; there is no (documented) way to access the data by different means. There is also no option to download a formatted list of search results or particular passages of text (not to speak about the ability to download whole texts or the whole corpus for textual analysis done by other tools).12 However, since virtually every view PHI can display is represented by a distinct URL, one can easily bookmark or share links to specific queries or passages.
10PHI has a minimalistic user interface with some undocumented and (in my view) unintuitively accessible features; however, after some experimentation, it can be used quite efficiently. There are three modes of operation: Browse, Search and Concordance.
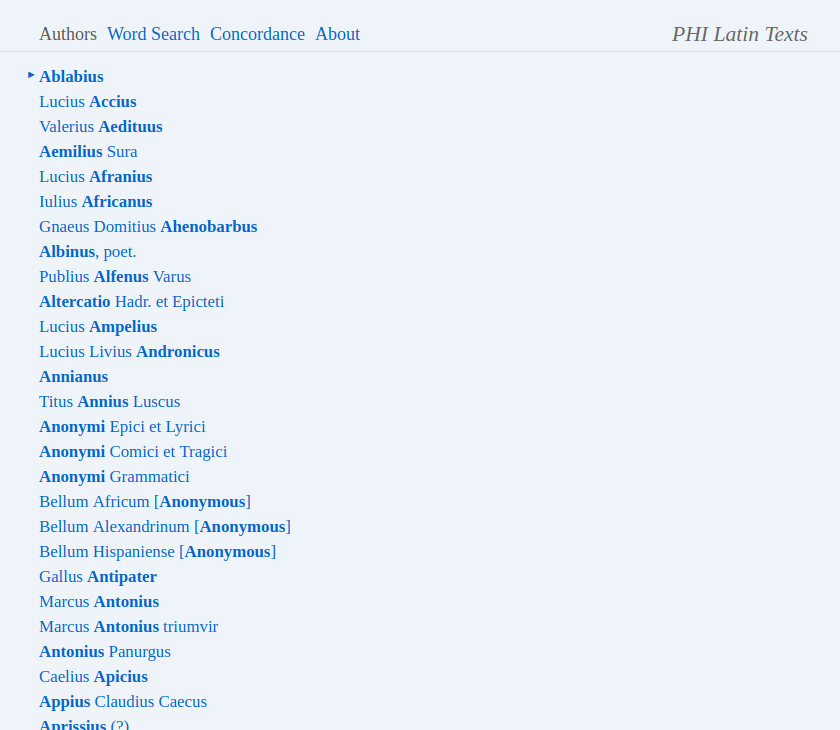
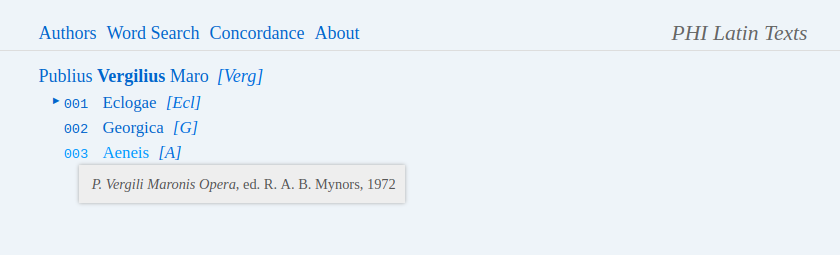
11After accepting a simple licence agreement (allowing ‘fair use’) on the opening page, the user is taken to the ‘Browse’ page,13 where an author can be selected from a list (in addition to scrolling, one can also begin to type in a name, see Fig. 1). Another page lists the texts – particular works and/or collections of fragments – by the selected author; hovering a title brings up the citation of the edition upon which the digital text is based (see Fig. 2). Unfortunately, this vital information is only accessible from here (and the ‘Canon of Latin Authors’ page),14 not while viewing a particular passage. This is an inconvenience, especially when the user is going through a list of search results including various authors and texts. Also displayed on the author’s page (in square brackets) are abbreviations for both author and texts, which can be used in search mode to filter results (see below).15
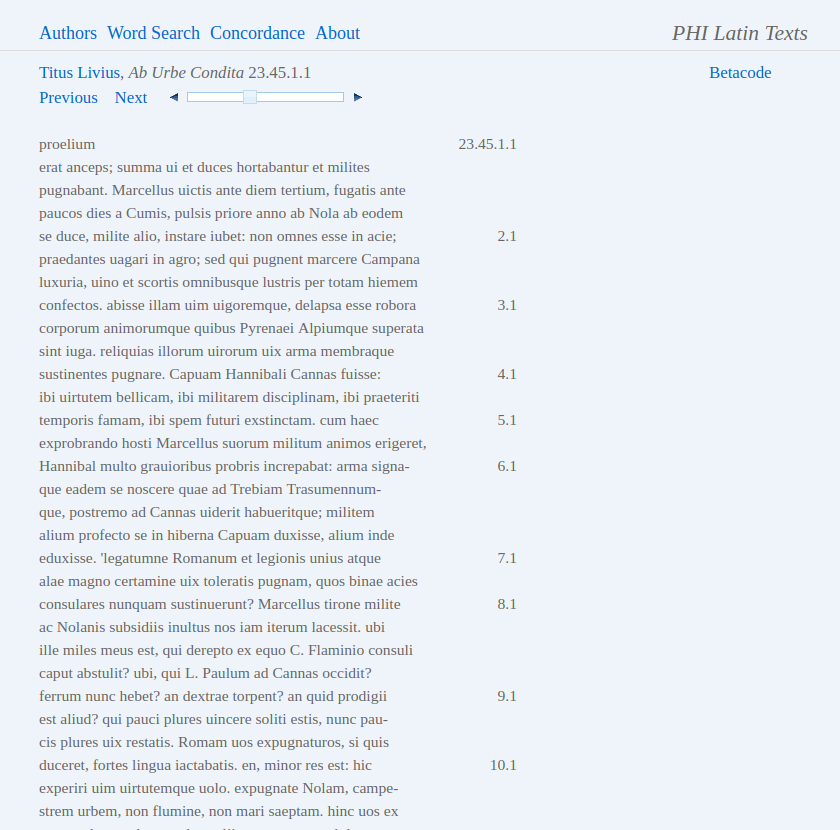
12Except for the shortest ones, texts are displayed on several pages (see Fig. 3). The length of segments making up a single page, however, is inconsistent and varies to a large degree, even between texts of similar genre and dimensions (e.g. for Vergil’s 12 book epic Aeneid one page equals one book, an average of 825 lines; the 15 books of Ovid’s Metamorphoses are segmented as pages of 30–40 lines). This inconsistency can be especially problematic for search operations (see below). For navigation, there are links pointing at the previous and the next page; a slider for jumping to any page; and the slider arrows for jumping to the beginning of major textual segments (usually, books). Apart from the fact that the slider arrows have sometimes different, sometimes the same function as the labeled links (a side effect of the above mentioned inconsistency in page lengths), the slider is not always convenient to use. Let us suppose, for example, that the user is looking for passage 23.45.4 in Livy (already used as an example above). Since this text is made up of 1765 pages in PHI (one page for each caput/chapter), it is very difficult to precisely select the right page. The navigation interface could be made much more convenient to use by the addition of a text field where one would simply enter “23.45.4” and jump to the page containing the passage. Given that PHI, as discussed above, can already handle URLs based on this standard citation scheme, this seems to be an improvement easy to implement.
13A very concise Latin/English dictionary can be opened for type-in search by clicking the ‘PHI Latin Texts’ logo in the upper right corner. I find the placement of this link quite unintuitive (especially given that this feature is undocumented), and it is not stated anywhere which dictionary is being used.
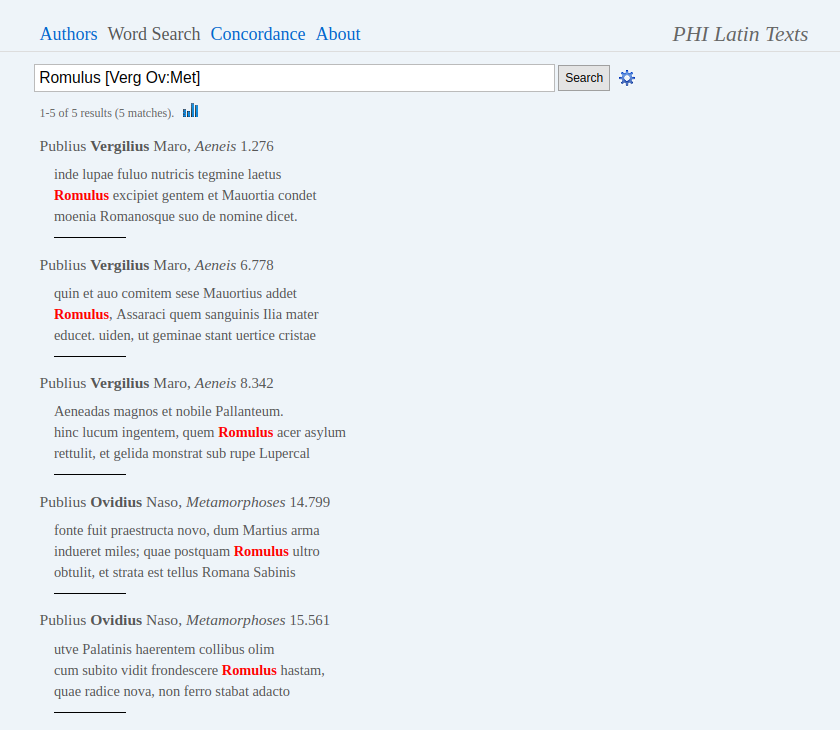
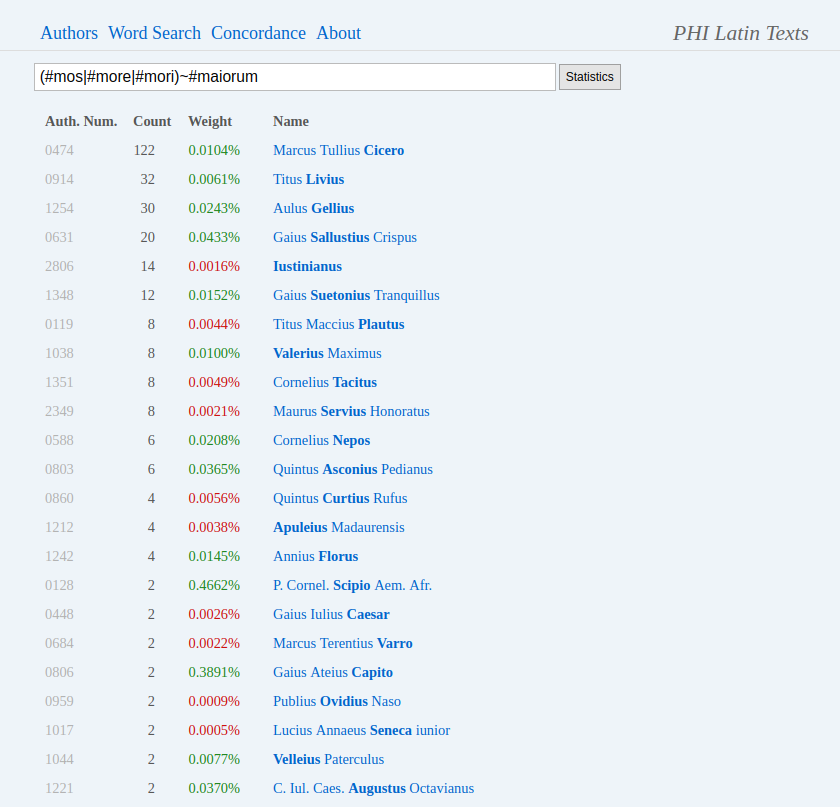
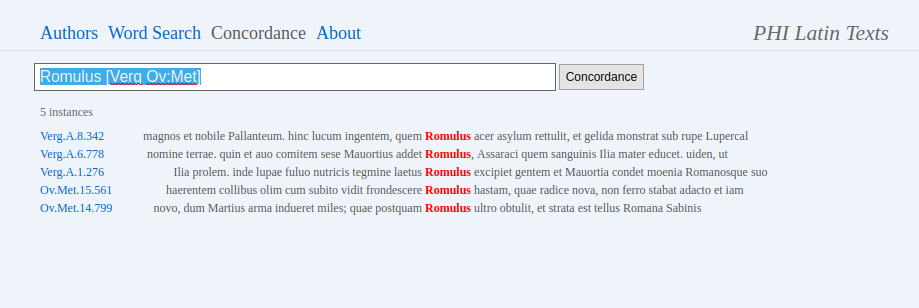
14The other main mode of operation is Search.16 The search page, again, is quite minimalistic: all parameters must be specified as part of the search phrase through logical operators. A short list of them can be displayed by clicking the cogwheel icon; a longer description of search operations (with more examples) is found on a separate page.17 Queries are corpus-wide by default, but one can narrow them down to specific authors and/or texts by adding the above discussed abbreviations in square brackets (for example, “Romulus [Verg Ov:Met]” limits a query to Vergil’s oeuvre and Ovid’s Metamorphoses); the selection of abbreviations is helped by type-in search. Results are displayed as a list of passages with the citation and the immediate context (3 lines) by default (also serving as links to the full passage in browsing mode, see Fig. 4); or, by clicking the ‘Statistics’ icon, as a re-sortable table listing absolute counts and weighted frequencies of occurrences by author (see Fig. 5). (Concordance mode18 can be considered basically as a third way to display search results, and will not be discussed separately, see Fig. 6).
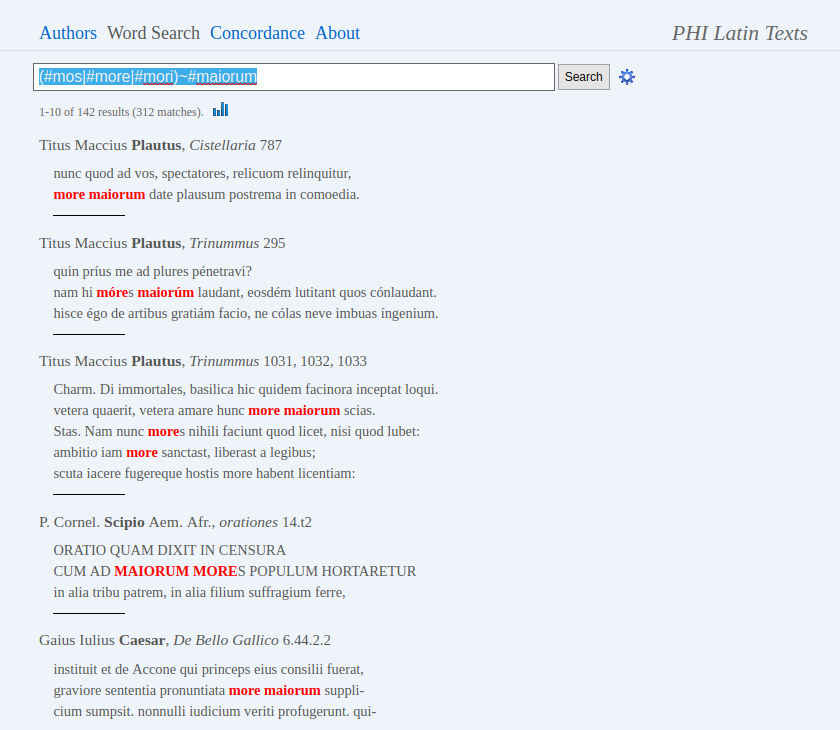
15By default, PHI looks for character strings rather than words; word boundaries must be signalled with the # operator. It is also not possible to search for all inflected forms of a word, unless the user types them in one by one, separated by | standing for the OR operator, or truncates words (which in most cases leads to a very high number of false positives, given the high inflection rate of Latin). The AND operator (&) looks for occurrences on the same page; and there is a proximity operator (~) as well to look for occurrences within about 100 characters (on the same page), in any relative order (the degree of proximity cannot be changed, see Fig. 7). In my experience, proximity search is perhaps the most useful feature of PHI, as it allows the user to efficiently look up noun phrases, for example, whose constituent words – given the relatively free word order of Latin – might not be found next to each other in a sentence. The reliability of proximity search, however, is somewhat limited by the fact that PHI is only looking for the co-occurrence of two strings on the same page. Page boundaries always correspond to sentence boundaries, thus noun phrases will always be found; but if one is looking for the thematic co-occurrence (rather than the grammatical conjunction) of two words, contexts where one word occurs in the last line of a page, the other in the first line of the next will not be found.
16These limitations notwithstanding, with some experimentation one can formulate very efficient search phrases; for example, “(#mos|#more|#mori)~#maiorum” returns all occurrences of the phrase mos maiorum (‘ancestral customs’, an important catchword in traditional Roman ideology), taking into regard inflected forms while minimizing the number of false positives. (Not surprisingly, by far the most occurrences for this phrase happen to be found in Cicero). Alternatively, if one has access to the CD-ROM version of PHI, Diogenes19 can be used to run even more complex queries, as it allows the use of regular expressions, can search for inflected forms (at least in single-word queries), and offers proximity search with a greater set of tunable parameters, not limited by the above discussed problem with page boundaries.
17PHI, as I hope to have shown in the review above, is a double-faced project. On the one hand, it is the late incarnation of a database designed three decades ago. As such, it is not based on up-to-date standards for the digital encoding, access and presentation of textual data. It is also not well documented and shows no signs of being developed further. The institutional background of PHI makes one hope that the database will remain online on the long term; but there is no indication on the website whether or not the corpus is safely archived. (An email address is provided on the website to contact the Institute with questions and comments; however, I have received no reply to my inquiries by the time this review is published.) Modernization of the whole underlying database would require substantial human and financial resources, of course; but at least some fine-tuning of the user interface (perhaps with community help) seems feasible and would be very welcome. On the other hand, PHI has proved to be in practice a wonderful tool (especially in intertextual research), widely used by classical philologists for decades now; and the generosity of the Packard Humanities Institute in making it freely accessible through an online interface deserves our gratitude. It will remain an important tool at least until the new generation of classical Latin corpora20 become available.21
Notes
1. For the (early) history of ‘digital classics’ see Brunner 1993, Crane 2004, and ‘The History of the TLG’ on the project’s website (https://web.archive.org/web/20170228114133/http://stephanus.tlg.uci.edu/history…). Some of the more recent developments are discussed in Bernstein—Coffee 2016.
2. A list of applications for Windows and Mac can be found on the TLG website (https://web.archive.org/web/20160427153442/http://www.tlg.uci.edu:80/about/cd_s…); missing from this list is Diogenes, a free and especially versatile application developed by Peter Heslin (Dept. of Classics and Ancient History at Durham University,
3. https://web.archive.org/web/20171005010120/http://stephanus.tlg.uci.edu/
4. https://web.archive.org/web/20171011020849/http://latin.packhum.org/
5. For another recent review of the online PHI, see Matthew Loar’s post (Apr. 17, 2017) on the Society for Classical Studies blog (https://web.archive.org/web/20171005124235/https://classicalstudies.org/scs-blo…).
6. PDL: https://web.archive.org/web/20171023204545/http://www.perseus.tufts.edu/hopper/ (reviewed for this issue of ride by Sarah Lang); LL: https://web.archive.org/web/20171011020819/http://www.thelatinlibrary.com/; LLT: https://web.archive.org/web/20170927031541/http://www.brepolis.net/; BTL: https://web.archive.org/web/20160317074929/http://www.degruyter.com:80/view/db/…. In this review, I will not consider the excellent Musisque Deoque database (https://web.archive.org/web/20171029101055/http://www.mqdq.it/public/), as it is a genre-specific collection of Latin poetic texts.
7. https://web.archive.org/web/20170705080503/http://latin.packhum.org/about
8. Another option for non-Christian late-antique Latin texts is Biblioteca digitale di testi latini tardoantichi (digilibLT), a resource I am not (yet) familiar with: https://web.archive.org/web/20170331001634/http://digiliblt.lett.unipmn.it/inde….
9. E. g. https://web.archive.org/web/20171029102206/http://latin.packhum.org/cit/Liv/AUC… for the above example.
10. https://web.archive.org/web/20170912044046/http://cwkb.org/
11. For documentation on Beta code, see https://web.archive.org/web/20170228090504/http://stephanus.tlg.uci.edu/encodin….
12. However, if one has access to the PHI CD-ROM, the corpus can be imported into and analyzed by the Classical Language Toolkit: https://web.archive.org/web/20170911143801/http://cltk.org/.
13. https://web.archive.org/web/20170705080758/http://latin.packhum.org/browse
14. https://web.archive.org/web/20170308033140/http://latin.packhum.org:80/canon
15. These abbreviations correspond to numerical codes which make up the link to the text itself: e.g. Vergil’s Aeneid = [Verg:A] = 690/3, https://web.archive.org/web/20161125054248/http://latin.packhum.org:80/loc/690/….
16. https://web.archive.org/web/20170705045034/http://latin.packhum.org/search
17. https://web.archive.org/web/20170102185851/http://latin.packhum.org:80/help/sea…
18. https://web.archive.org/web/20170705072055/http://latin.packhum.org/concordance
19. https://web.archive.org/web/20171019132903/http://community.dur.ac.uk/p.j.hesli…
20. See e. g. the Open Greek and Latin Project (https://web.archive.org/web/20171210182145/http://www.dh.uni-leipzig.de/wo/proj…), aiming at producing XML versions of at least one print edition of each work; the Digital Latin Library of the Society for Classical Studies (https://web.archive.org/web/20180122103901/https://digitallatin.org/) is planned to be a series of new digital critical editions.
21. This review was written with support by the ÚNKP-17-4 New National Excellence Program of the Ministry of Human Capacities (Hungary).
References
- Brunner, Theodore F. 1993. ‘Classics and the Computer: The History,’ in: Accessing Antiquity. The Computerization of Classical Databases, edited by Jon Solomon, Tucson: University of Arizona Press, 10–33.
- Crane, Gregory. 2004. ‘Classics and the Computer: An End of the History,’ in: A Companion to Digital Humanities, edited by Susan Schreibman, Ray Siemens, John Unsworth, Oxford: Blackwell Publishing, 46–55 and online at: https://web.archive.org/web/20160506084849/http://www.digitalhumanities.org/com…
- Bernstein, Neil and Coffee, Neil (eds.). 2016. Digital Methods and Classical Studies = Digital Humanities Quarterly 10.2, https://web.archive.org/web/20170707073624/http://www.digitalhumanities.org/dhq…