ChatGPT, OpenAI (ed.), 2022. https://openai.com/ (Last Accessed: 01.02.2026). Reviewed by ![]() Martina Scholger (University of Graz), martina.scholger@uni-graz.at and
Martina Scholger (University of Graz), martina.scholger@uni-graz.at and ![]() Roman Bleier (University of Graz), roman.bleier@uni-graz.at. ||
Roman Bleier (University of Graz), roman.bleier@uni-graz.at. ||
Abstract:
Large language models such as OpenAI’s ChatGPT have rapidly become prominent tools in academic contexts, including digital scholarly editing. Although not originally designed for editorial practice, they are increasingly integrated into experimental editorial workflows. This review assesses its potential to support key editorial tasks and surveys recent literature on their use in digital scholarly editing. Drawing on published case studies and our own experiments, we analyze the benefits and limitations of employing ChatGPT at different stages of creating and analyzing digital scholarly editions, including transcription, TEI encoding, and named-entity recognition. At the same time, the review addresses significant concerns. As a commercial and largely closed system, ChatGPT operates as a ‘black box’ that allows only indirect control through prompting, raising challenges for transparency and reproducibility in academic contexts. Issues of model bias and data governance must be carefully considered when integrating such tools into research workflows. ChatGPT should therefore be adopted cautiously and critically. Nevertheless, its capacity to lower technical barriers and to consolidate tasks that previously required multiple tools and advanced programming skills makes it, or similar artificial intelligence tools, a potentially valuable assistant in digital editing workflows.
Introduction
1In the rapidly evolving landscape of the Digital Humanities, large language models (LLMs)1 have become prominent tools for numerous tasks, including text analysis, classification, and language translation. This review examines ChatGPT’s capabilities as an assisting tool for digital scholarly editing tasks. ChatGPT was selected due to its growing media presence and widespread adoption within the humanities community, including institutional deployments at universities such as the University of Graz, where the authors are affiliated.2
2Introduced in November 2022 (OpenAI 2024), the chatbot ChatGPT is a generative artificial intelligence (AI) system that communicates through natural language, processing user inputs—known as prompts—to produce textual responses. ChatGPT is developed by OpenAI, a company founded in 2015 in San Francisco by a group of machine learning experts, research engineers, and scientists.3 There is a huge interdisciplinary team of developers behind the system: the GPT-4 technical report lists 280 co-authors (OpenAI 2024), and financial support is provided by individuals and companies. ChatGPT is offered in multiple subscription tiers and model variants, each with different capabilities, usage limits, and available tools such as web browsing, image generation, and data analysis. During the revision period for this article, the default models and available features changed notably across tiers, illustrating the platform’s rapid evolution.
3 The chatbot can be used as an assisting tool for scholars in the process of editing, annotating, and curating (historical) texts. The authors evaluate ChatGPT primarily as practitioner-users, i.e., as editors working with the web-based graphical user interface, rather than as developers engaging with the underlying models or APIs. All experiments were performed using the ChatGPT web interface, specifically the GPT-4o model, accessed between July 2024 and July 2025, under both free and Plus tier access. The source material used in the experiments comes from digital edition projects in which the authors are involved, namely Joseph von Hammer-Purgstall. Korrespondenz (Höflechner et al. 2025) and Der Reichstag zu Regensburg 1576 (Leeb et al. 2023). While the focus of the review is clearly on the usability and constraints of the AI tool for editorial work, ethical questions that editors might face are also discussed, such as issues of reproducibility and citability of stable versions, which poses challenges for the transparency and documentation of editorial decisions. However, given the pace of development in both models and interface features, this review represents a time-bound snapshot rather than a comprehensive assessment.
Methods and Implementation
4The technical architecture of ChatGPT relies on Generative Pre-trained Transformer (GPT) models, which are fine-tuned for natural conversation using a combination of supervised learning and reinforcement learning from human feedback. These LLMs belong to the broader class of foundation models, which are designed to support multiple downstream applications rather than being optimized for a particular, narrowly defined task. Therefore, ChatGPT can in principle be applied to a wide range of tasks at different stages of a digital scholarly editing workflow.
Training Data, Transparency, and Reproducibility
5The exact training data of the underlying models is not publicly disclosed, and the models themselves are not openly available. According to OpenAI, training data consists of “information that is publicly available on the internet, information that we license from third parties, and information that our users or our human trainers provide”.4 This limited transparency has been widely criticized, particularly in scholarly contexts, where the provenance of training data is an important concern. Another significant limitation for scholarly work relates to reproducibility. Even when identical prompts are used, ChatGPT does not reliably produce identical outputs. This behavior reflects the inherent non-deterministic nature of LLMs, which predict token probabilities in context based on the training data (Ouyang et al. 2023). This complicates the documentation, verification, and long-term traceability of editorial decisions.
6Another factor affecting reproducibility concerns the availability of different model versions within the ChatGPT platform. As of June 2025, free-tier users have access by default to GPT-4o, OpenAI’s flagship multimodal model, though access is subject to usage limits. Once these limits are reached, usage automatically defaults to a smaller, cost-efficient fallback. Users of subscription tiers such as Plus, Pro, or Team receive higher usage limits and access to a wider range of models through the model selector, including models optimized for complex reasoning tasks, high-performance multimodal interaction, and lightweight, cost-efficient processing. The presence of multiple model versions within a single platform therefore introduces an additional layer of unpredictability for scholarly workflows.
Interaction Model and Prompting
7ChatGPT operates through a conversational interface in which users interact with the system using natural language prompts. While text is the primary input modality, interactions can also begin with images or voice. A prompt is the instruction or query provided to the model, ranging from simple questions to complex scenarios, directing the LLM in its response generation. In addition to user prompts, the system relies on internal system prompts that shape the model behavior, but remain invisible to users. Prompt engineering refers to the practice of designing prompts to guide model outputs effectively. Considerations of prompt length and structure are also relevant, as model inputs are processed as tokens and subject to context window limits. There are various prompting techniques, such as zero-shot, few-shot, and chain-of-thought prompting, each designed to approach the model differently based on the complexity of the task (Saravia 2022). In editorial contexts, careful prompting is essential for achieving consistent results, particularly when tasks involve formalized output formats or domain-specific conventions. Mastering prompt engineering has become its own discipline and is particularly important in digital humanities contexts, where tasks frequently involve specialized terminology, historical language material, and encoding standards that require precise instructions (Saravia 2022, Pollin 2025).
8All inputs and outputs processed by ChatGPT are internally segmented into tokens, which constitute the basic unit for both text processing and usage accounting.
Tokens are the building blocks of text that OpenAI models process. They can be as short as a single character or as long as a full word, depending on the language and context. Spaces, punctuation, and partial words all contribute to token counts. This is how the API internally segments your text before generating a response.5
9How exactly tokens are calculated is often not immediately intuitive for users. OpenAI suggests that, as a rule of thumb, for English texts one token corresponds to approximately four characters, or about three-quarters of a word. Consequently, 100 tokens amount to roughly 75 English words. OpenAI provides an online tokenizer that allows users to test how specific inputs are segmented into tokens.6 While this approximation is slightly vague, an additional complication is that tokenization is language-dependent. This is especially relevant for digital scholarly editing, which very often involves historical texts in languages other than contemporary English.
Configuration and Personalization
10Beyond prompt-level interaction, ChatGPT also allows users to configure model behavior through customizable applications known as Custom GPTs. For creating them, no programming knowledge is necessary. The configuration screen allows you to enter a picture, a name of the GPT, a short description, detailed instructions, a conversation starter to facilitate the start of a conversation, and the upload of an extra knowledge base. When such files are provided, the system can retrieve relevant passages from them during response generation, thereby implementing a form of retrieval-augmented generation (RAG). It is recommended to provide the additional knowledge in a minimalistic format (e.g., JSON or Markdown) to save tokens instead of ‘chatty’ formats like XML, where each tag consumes tokens. While this built-in retrieval mechanism is suitable for small-scale text documents, larger corpora typically require interfacing with external databases.7 Custom GPTs can be kept for internal use only or shared with the broader community; they remain bound to OpenAI’s infrastructure and do not constitute independent editorial tools.
11ChatGPT can be individually configured using ‘custom instructions’, a personalization feature distinct from Custom GPTs, available in the user settings. These allow users to provide details about their interests and working context and to specify how the model should respond, for example, by indicating a preferred tone or level of detail. The instructions persist across conversations so that the user does not have to repeat these preferences in each prompt.
Input, Output, and Data Analysis Capabilities
12ChatGPT can handle and process text in various data formats like plain text, XML, HTML, JSON, CSV, or Markdown, as well as multimodal inputs such as image, video, and audio as input. Likewise, it can generate output in most textual data formats; in addition, newer multimodal models support synthesized audio output, while the generation of standalone video files is not natively supported in the standard ChatGPT interface. Advanced Data Analysis (ADA), an integrated capability of GPT-4-class models, further expands its functionalities to the automatic generation of Python code for performing exploratory data analysis tasks. It can process structured data formats, including Excel, CSV, and JSON, and produce outputs as Python code, statistical summaries, visualizations, charts, interactive tables, and more, thereby supporting eexploratory data analysis within a single environment
13For developers, OpenAI provides convenient and well-documented access to its API through multiple interfaces, including the programming language Python, the cURL command-line tool for making HTTP requests to APIs, and Node.js, a widely used JavaScript runtime environment to build applications, provided one has an API key. The API supports integration into a wide range of software systems, applications and services. However, the focus of this article is the chatbot interface, and the API and its development capabilities will therefore not be discussed in detail.
Positioning within the LLM Landscape
14ChatGPT exists within a broader and rapidly evolving ecosystem of generative language models. Proprietary systems include Claude by Anthropic, Gemini by Google, as well as models integrated into platforms like Microsoft Copilot. At the same time, open-weight and open-source models are advancing rapidly and in some benchmarks are even outperforming proprietary systems in certain tasks (Chen et al. 2024). Prominent examples include the Llama family developed by Meta, Mistral AI’s Mistral and Mixtral models, and Alibaba’s Qwen series.
15When assessing a language model’s openness, it is important to differentiate between open-source models and open-weight models. Open source refers to sharing the full source code, the underlying algorithms, training methods, and data, while open-weight models only share the pretrained model parameters, which allows use but limits transparency and control. Open-weight models are easier to use but less transparent, while open-source promotes transparency and allows modification, but also requires more developer effort (Ramlochan 2023). For digital scholarly editing, these distinctions are relevant for sustainability, inspectability, and long-term reuse. The current leading open-source models can be consulted at the Chatbot Arena.8
Application for Digital Scholarly Editing
16In conceptualizing how generative AI might support scholarly editing, the Institute for Documentology and Scholarly Editing (IDE) has proposed a processing pipeline (Pollin et al. 2025), tracing the path from source material through edition as data to edition as publication via intermediate editorial products such as digital images, transcriptions, and the user interface. It further differentiates between structural tasks (e.g., planning, documentation, tool integration, quality control) and operational tasks (e.g., text recognition, entity recognition, normalization, enrichment). Mapping ChatGPT’s capabilities onto this pipeline helps locate the stages at which it may be effectively integrated into editorial workflows, and where their limitations become apparent. We will attempt a brief evaluation of some tasks in this section.
17We have already mentioned the multifaceted applications of ChatGPT as a tool to support editorial work, ranging from text summarization and translation to automated XML/TEI annotation and other natural language processing (NLP) tasks. It can also be used as a ‘buddy’ to provide constructive feedback on existing data models or XML/TEI code, helping to identify inconsistencies or suggest alternative solutions. Furthermore, ChatGPT can assist in the development of small programs or scripts for the web presentation or data analysis of an edition, utilizing Promptotyping, a prompt engineering method in LLM-based software development (Pollin 2026).
18From a utility perspective, ChatGPT primarily supports exploratory and preparatory stages of editorial work rather than final, authoritative decisions, as its non-deterministic nature and lack of stable versioning limit scholarly reproducibility. While this challenges academic rigor, the non-deterministic behavior can also be used as an advantage. Editors can generate multiple versions of the same output (e.g., alternative TEI encodings) and critically identify the optimal encoding approach. In this way, non-reproducibility can function as a form of digital hermeneutics, potentially transforming what appears to be a limitation into a tool for deeper interpretive engagement with editorial decisions.
Examples and Current Uses of Generative AI in Digital Scholarly Editing
19GPT models are generally considered not to be trained on specific domains or tasks, although user-guided fine-tuning can be applied to that end. They are general-purpose models that can assist in different tasks related to the digital editing pipeline, from data creation to final publication. One area of experiments includes custom GPTs, i.e., user-configured applications built on top of a pre-trained GPT model. Examples include teiCrafter, an “expert automaton for converting plain text to TEI XML” (Pollin 2024); TEI Scholar (Jankovic); and TEI Lex 0 Converter (Miyagawa).
20Beyond individual tools, broader community efforts further illustrate these developments. A workshop at the DHd 2024 conference in Passau, organized by the Institute for Documentology and Scholarly Editing (IDE), provided a broad overview of ongoing experiments with generative language models in digital scholarly editing (Pollin et al. 2024). The ten contributions covered a wide range of editorial tasks, including transcription, OCR post-correction, markup generation, normalization, named entity recognition, annotation, translation, and text summarization. As demonstrated in Pollin’s workshop series, generative AI can be applied across diverse DH use-cases: from transforming unstructured data into TEI to generating and modeling RDF data to data analysis and visualization (Pollin 2025). Alongside these exploratory applications, research has emphasized the need for robust pipelines and systematic evaluation in LLM-assisted scholarly workflows. Recent contributions assess, for example, the quality and reliability of LLM-assisted TEI encoding (Strutz and Vogeler 2025, Strutz forthcoming), the automated handling and resolution of editorial interventions (Strutz and Scholger 2025), and the automated extraction and normalization of metadata from historical letter transcriptions (Strutz and Scholger 2026). Galka and Vogeler compare the integration of different LLMs within a workflow for adding named entity recognition annotations (2026). These studies highlight both the potential of LLMs for complex, context-sensitive tasks and the methodological challenges that remain.
21In order to evaluate ChatGPT’s practical value for concrete editorial tasks, we selected two common use cases: (1) converting plain text into TEI-compliant XML, and (2) identifying and classifying named entities. All experiments were performed using GPT-4o in the browser interface. For more elaborate examples, we refer to slides including chat protocols in Pollin 2025.
Testing ChatGPT with a Letter from the Joseph von Hammer-Purgstall. Korrespondenz
22In the first example, a letter from the digital edition Joseph von Hammer-Purgstall. Korrespondenz (Höflechner et al. 2025) was provided as plain text and should be encoded following the Guidelines of the TEI (TEI Consortium 2026). The correspondence spans the late eighteenth to mid-nineteenth century and constitutes a multilingual scholarly exchange within the context of Oriental studies.
Euer Gnaden,
Unterzeichneter1 bittet um die gnädige Erlaubnis, künftigen Sonntag die Redoute2 besuchen zu dürfen3, weil er
1.) im letzten und sechsten Jahre seiner Studien und bereits ein Jahr länger an der Akademie ist als es seine Vorfahren waren, da ihnen diese Erlaubnis erteilt wurde.
2.) auf das ihm jederzeit von S[einer] H[ochwohlgeboren] dem Herrn Direktor erteilte Zeugnis seines guten Verhaltens und sittlichen Betragen stolz ist, und sich daher schmeichelt, dass die Besorgnis einiger daraus entstehenden üblen Folgen bei ihm nicht statt haben dürfte.
3.) die Vorschrift einer für diesen Fall geforderten anständigen und sicheren Begleitung nicht besser erfüllt haben könnte, indem er in der Gesellschaft der Frau Schwester des Herrn Direktors sich befinden wird.
Den 20ten Hornung 1794
Joseph Hammer1.) PvTh D.2.1.14.
2.) Eine Tanzveranstaltung oder auch ein eleganter Maskenball. Um welche derartige Veranstaltung es sich hier handelt, ist nicht feststellbar.
3.) Die Erledigung durch Jenisch s. das nachfolgende Stück, findet sich auf demselben Blatt wie die vorangegangene Bitte HPs mit dem Vermerk „Von der Kanzlei den 20. Hornung 1794“.(Hammer-Purgstall an Jenisch 1794)


Testing ChatGPT with a Letter from the Edition Der Reichstag zu Regensburg 1576
24In the second example, the same TEI annotation task was applied to reports of envoys present at the Imperial Diet of the Holy Roman Empire that was held in Regensburg in the year 1576 (Leeb et al. 2023). The envoys, Dr. Wolfgang Eulenbeck and Dr. Andreas Paulus, reported regularly to Prince-elector (Kurfürst) August von Sachsen, who was not present at the Imperial Diet. The form and structure of these reports are very similar to the above letter from the Joseph von Hammer-Purgstall. Korrespondenz. However, the significant difference is that they were written three centuries earlier, in Early New High German. The correspondence between the envoys and August von Sachsen is published in the edition Der Reichstag zu Regensburg 1576.
25 The following quote shows the plain text of the letter from May 9 1576, to August von Sachsen:
Neunden Maii, Regenspurgk rhäte. Präs. Annaburg, 12. Maii anno 76. Zu s. kfl. Gn. henden.
Durchlauchtigster hochgeborner churfurst, ewern kfl. Gn. seint unsere underthenigste gehorsame dienste jeder zeit mit trewem vleiß zuvorn. Gnedigster herre.
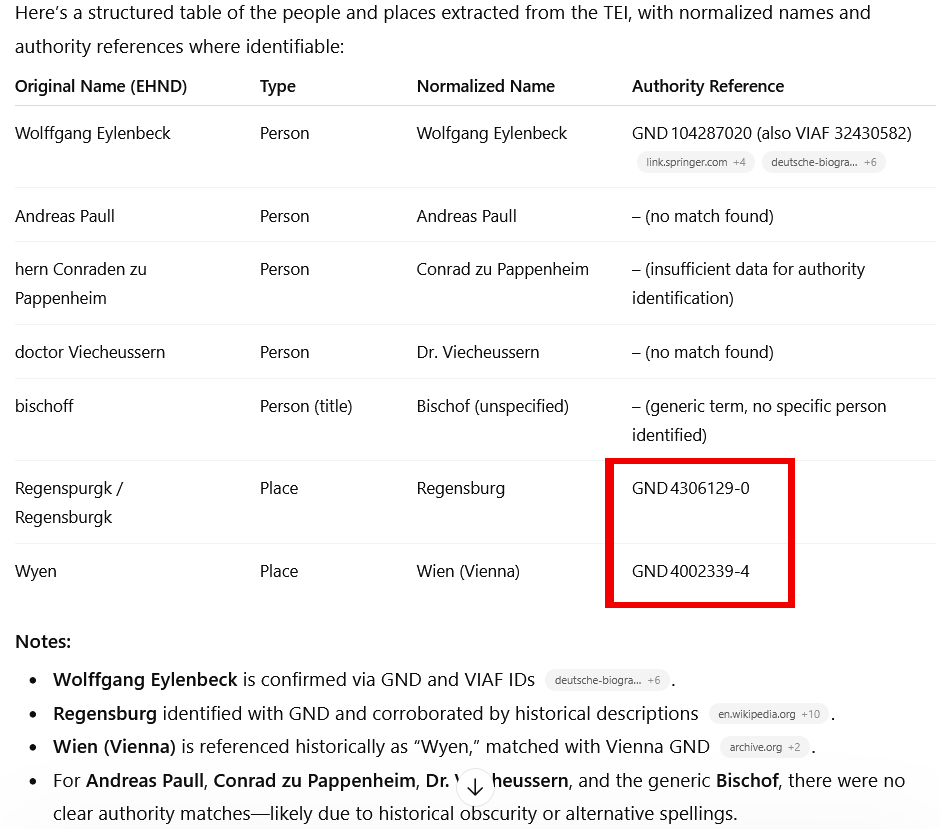
Auf euer kfl. Gn. gnedigsten bevelch und uns zugeschickter instruction haben wir uns aufn wegk nach Regensburgk erhoben, und seint gestern umb acht schlage vor mittage alhier ankommen. Und wiewol wir under wegs verstendigt, als solte die röm. ksl. Mt. auf den vierzehenden tag ditz monats Maii alhie angelangen, so werden wir doch durch des Reichs marschalch alhier berichtet, das sich irer ksl. Mt. aufbruch zu Wyen bis in mitten ermelts monats verweilett, und ire Mt. wenig vor ende desselben alhier ankommen werden, inmassen euer kfl. Gn. aus inligender copey der höchstgedachten ksl. Mt. schreiben an den bischoff [1v] alhier, item hern Conraden zu Pappenheim und doctor Viecheussern gnedigst haben zuersehen.
So thuen euern kfl. Gn. wir hirbey underthenigst ein vorzeichnus ubersenden, was vor gesandten (derer doch wenig sein) bis auf itzo alhier angelangt.
Und, euer kfl. Gn. mit underthenigstem gehorsamb trewe dienste zuleisten, seint wir schuldig und geflissen. Datum Regensburgk, den neunden Maii anno 76.
Ewer kfl. Gn.
underthenigste gehorsame
Wolffgang Eylenbeck, Dr.
Andreas Paull propria[?](Bericht: Dr. Wolfgang Eulenbeck und Dr. Andreas Paulus an Kurfürst August von Sachsen, 1576-05-09)

27 Close observation of the result shows that some text is missing. For some reason, the part of the opener indicating when the letter was presented to August von Sachsen: ‘Präs. Annaburg, 12. Maii anno 76’ is missing. Furthermore, identification and expansion of abbreviations is a challenge. While abbreviations, such as ‘s.’, ‘Mt.’ and ‘kfl.’ are correctly resolved, others were not even identified as abbreviations, e.g., ‘Gn.’, or words were incorrectly identified as abbreviations, e.g., ‘ewern’, ‘bevelch’, ‘instruction’. This can easily be resolved by providing a list of the abbreviations used in editions of the Imperial Diets.9 Dates are precisely tagged and correctly normalized using the @when attribute. However, ChatGPT does not automatically take the Gregorian calendar reform into consideration. It has to be explicitly mentioned to add @calendar.

User Experience and Ethical Considerations
Access and User Interface
29ChatGPT can be accessed via the OpenAI website, and an API is available for programmatic use. The tool requires minimal setup, and the web interface is minimalistic and straightforward. It works well on all modern web browsers, and a ChatGPT app is available for mobile devices. Users require internet access and an OpenAI account. The interface is designed primarily for conversational interaction—asking questions and receiving responses—and keeps this core functionality readily accessible. Critical remarks have been raised, however, regarding its simplicity and limited customization options (e.g., Sebastian 2023). Additional services beyond the free tier, including expanded API usage and processing capabilities, are only available under a pay plan based on OpenAI’s token system.10 This makes it less attractive for sustained scholarly work and creates unequal conditions, as not all academics or projects might have the resources to cover the costs. It is also worth noting that access to ChatGPT varies globally.11 In regions where the tool is restricted, such as China, alternatives like DeepSeek and Ernie Bot are available (Yang 2023, Wikipedia contributors 2024). While these tools offer similar functionalities, their effectiveness for digital scholarly editing would require separate evaluation.
Documentation, Multilinguality, and Accessibility
30The various language models used within ChatGPT, and their differences, are documented and compared on the OpenAI website.12 OpenAI also has a help center and maintains a developer forum, where mostly API-related issues are discussed. ChatGPT has a big user community and is widely used; therefore, if you run into a general problem, the chance is very high that someone else already had a similar problem, and the solution can be found online. OpenAI also provides documentation and guidelines for the use of the tool. For instance, guidelines for prompt engineering that explain strategies and suggestions for crafting effective prompts to get better results from ChatGPT.13 In addition to the material provided by OpenAI, numerous introductions and documentation about working with ChatGPT were developed by individuals, institutions, and organizations all over the world, including subject-specific introductions for Digital Humanities and digital scholarly editing (e.g. Pollin 2025).
31ChatGPT is described as a multilingual chatbot that can communicate in over 50 languages.14 It also provides the possibility to translate from one language into another, making it a competitor for Google Translate, DeepL, and similar services (Quillen 2023; PCMAG 2023). The speech-to-text Audio API based on the Whisper model provides support for many languages: while it was trained on 98 languages, for only about 58 of them is the word error rate lower than 50%—a limitation relevant for projects involving non-English or historical language material.15
32AI tools, including ChatGPT, are frequently discussed in the context of accessibility and the provision of barrier-free content. The OpenAI web interface is simplistic and screen-reader friendly. But the actual benefit comes from the use of the ChatGPT API in various new applications. For instance, such systems can generate automated descriptions of images, real-time captions, and simplify complex texts into easier language.16
Ethical Dimensions
33 There is a broad spectrum of ethical concerns being discussed in the context of AI use. Applying ChatGPT in an editorial workflow should therefore be carefully considered, and not only its benefits but also its broader implications must be taken into account. For instance, the increase in power consumption of technology companies and the building of enormous data centers cause environmental issues, which call for sustainable solutions when adopting AI in daily work (Rohde et al. 2024).
34 The responsibility for output that an AI tool produces is particularly important in an editorial context. ChatGPT and similar tools can create image-based transcriptions, translations, and, as we have seen, also XML/TEI markup. Nevertheless, the tool may also introduce errors and interpretations of the source material not intended by the editor. Like in all AI-driven workflows, also in editorial practices, the concept of trustworthy AI, focusing on transparency, accountability, reliability, and fairness, should also be considered (AI HLEG 2019, Pope 2024). A comprehensive overview and analysis of the various discussions surrounding the ethical dimensions is provided by Stahl and Eke (2024). Our final section focuses primarily on questions of data governance, transparency through citation, and bias.
35OpenAI assures its users that all data shared with ChatGPT is encrypted, and that inputs and outputs they receive are rightfully theirs.17 Nevertheless, there are concerns that OpenAI uses input data for training purposes, that sensitive information may end up in the company’s database and become available to other users, and that OpenAI collects substantial data about its users and their behavior (Merton-McCann 2023).
36In academic contexts—research, academic writing, and teaching—the question of how to cite (and acknowledge) the use of ChatGPT poses several issues. Conversations are tightly bound to a user account, and there are no permalinks, no DOI, and no URL that allows for persistent sharing. There is not yet a general consensus on how to cite ChatGPT conversations.18 However, ChatGPT is usually not considered an author. This also means that ChatGPT—like any AI—cannot claim copyright, and any AI-generated output is automatically considered public domain (Scholger 2025). APA, for example, suggests that ‘chats’ with an AI cannot be cited as personal communications, as there is no person communicating.19 It is typically recommended to include the prompt or the entire conversation for reference, for instance in an appendix.20 This reminds us of the recommendations from the early 2000s to print out entire websites and attach them to a publication—an approach that can quickly become unwieldy, as conversations with ChatGPT can be quite extensive.
37Finally, we briefly address the question of bias. Even if we ‘talk’ to a machine, ChatGPT is not objective. The models are trained on an enormous amount of data, most of it from a North American and European context, and the biases introduced through that data influence its responses. Gender, racial, religious, age, or political bias, and other negative behaviors have been identified and criticized.21 OpenAI provides a disclaimer about bias and stereotypes in ChatGPT responses on its website, suggesting that users should be careful with generated content, particularly when dealing with culturally sensitive or historically situated material.22
Conclusion
38ChatGPT is not a tool that was explicitly developed with the digital humanities or the scholarly editing community in mind. Nevertheless, it has a wide range of potential applications for researchers and editors, and can support different stages of the development or analysis of digital editions. It can assist with transcription and data creation, support the development of scripts for data processing and analysis, and facilitate related tasks.
39There is still relatively little research and benchmarks on the use of LLMs for editorial purposes, and the possibilities of what can be done with ChatGPT and similar AI tools are constantly changing. We are aware that the evaluation of such technology is only a snapshot that might not be relevant in a couple of months, and that all predictions for future developments are quite difficult, as development moves so quickly. As we outlined in the article, we chose to evaluate ChatGPT (GPT-4o) over other LLMs, as it is well-known and currently widely used by humanities scholars.
40Several limitations significantly constrain the use of ChatGPT as a tool for scholarly editing. First, the development of the tool is closed off as it is a commercial product. For editors, this results in a black-box situation that can be vaguely controlled using prompts. If prompts are not carefully crafted, the results can be misleading or even totally wrong. Second, it remains unclear how OpenAI handles the data provided by users and to what extent the data is used to train future models. Therefore, users have been warned to be careful and not to share sensitive or unpublished material with AI. For scholarly editing, this significantly restricts the range of sources for which ChatGPT can be used responsibly. Third, while the chatbot interface is suitable for small-scale experiments and exploratory tasks, complex multi-stage editorial workflows for an entire corpus—from the TEI encoding to the recognition of named entities and their enrichment with norm data—can only be effectively implemented via the API. The associated costs cannot be covered by every project and also contradict the principles of an open-knowledge society and equal access to research. This is why it is so important that we focus more on developments in the area of open-source LLMs in the future. Finally, ethical issues caused by the bias in the models have to be kept in mind when incorporating these tools into scholarly workflows.
41The use cases and literature presented in this review demonstrate ChatGPT’s high potential as an assistant for digital editing. Tasks that previously required several tools and technical expertise can now be performed with comparatively little effort using carefully designed prompting instructions. At the same time, we have also discussed that the quality of the results can diverge depending on the source material of the edition and a user’s ability to craft ‘good prompts’. In any case, a human editor must remain in the loop to control, evaluate, and, if necessary, further process the output. This is especially highlighted by our little experiment using German texts from two different historical language periods. It shows that ChatGPT works less effectively with non-standard and historical language material. As models continue to improve and open-source alternatives mature, the more pressing question for the digital editing community is no longer whether to engage with these tools, but how to use them in transparent, critically informed, and methodologically rigorous ways.
Notes
[1] LLMs are trained with deep-learning algorithms on vast corpora of web pages, books and articles to learn the patterns and structures of language. With multi-billion-parameter architectures, they are able to generate context-aware text.
[2] Martina Scholger and Roman Bleier are both affiliated with the Department of Digital Humanities at the University of Graz, where they work in the field of digital scholarly editing—Scholger as a senior scientist and Bleier as a postdoctoral researcher. We thank Christopher Pollin of DH Craft for reading an early draft of this article and for providing valuable feedback and helpful suggestions, and Thea Schaaf for proofreading.
[3] Brockman, Sutskever, and OpenAI 2015, here: https://web.archive.org/web/20241007222900/https://openai.com/blog/introducing-openai/.
[4] OpenAI 2025, here: https://web.archive.org/web/20240913163752/https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-language-models-are-developed.
[5] OpenAI 2025, here: https://web.archive.org/web/20251012012828/https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them.
[6] https://web.archive.org/web/20251008185403/https://platform.openai.com/tokenizer/.
[7] Saravia 2022, here https://web.archive.org/web/20250808170700/https://www.promptingguide.ai/techniques/rag.
[8] An overview of leading chatbots is provided by the ‘Chatbot Arena’ (Chiang et al. 2024), an online platform that ranks LLMs based on crowdsourced human preference evaluations.
[9] Such a list is provided by every edition of the Imperial Diets: e.g., https://gams.uni-graz.at/o:rta1576.bt17331b5u.
[10] OpenAI uses a token system for input, output, and training usage. https://web.archive.org/web/20260314111058/https://chatgpt.com/pricing/. But this constantly changes.
[11] For a brief period of time in 2023 even in Italy it was banned due to issues with the data protection regulations, DigitalTrends: https://web.archive.org/web/20260316110636/https://www.digitaltrends.com/computing/these-countries-chatgpt-banned/. See also a recent article (June 2024) about China: https://web.archive.org/web/20240630064038/https://edition.cnn.com/2024/06/21/tech/apple-ai-chatgpt-ban-china/index.html.
[12] https://web.archive.org/web/20260317093543/https://developers.openai.com/api/docs/models.
[13] https://web.archive.org/web/20260308121716/https://developers.openai.com/api/docs/guides/prompt-engineering.
[14] The chatbot and its user interface are constantly evolving and updated. OpenAI: How to use ChatGPT in a language other than English (alpha), https://help.openai.com/en/articles/8357869-how-to-use-chatgpt-in-a-language-other-than-english-alpha.
[15] OpenAI: Speech to text: https://platform.openai.com/docs/guides/speech-to-text; https://platform.openai.com/docs/guides/speech-to-text/supported-languages.
[16] https://web.archive.org/web/20260311135431/https://netzpolitik.org/2023/gpt-4-das-naechste-grosse-ding-fuer-digitale-zugaenglichkeit/.
[17] https://web.archive.org/web/20260312100111/https://openai.com/enterprise-privacy/.
[18] As an example we provide here the recommendation by the University of Graz, last update 18.08.2025: https://lehren-und-lernen-mit-ki.uni-graz.at/de/ki-nutzung-kennzeichnen/.
[19] ‘Unfortunately, the results of a ChatGPT “chat” are not retrievable by other readers, and although nonretrievable data or quotations in APA Style papers are usually cited as personal communications, with ChatGPT-generated text there is no person communicating.’ https://apastyle.apa.org/blog/how-to-cite-chatgpt.
[20] APA policy on the use of generative artificial intelligence (AI) in scholarly materials, in: APA Publishing Policies (Aug. 2023): https://web.archive.org/web/20260301102507/https://www.apa.org/pubs/journals/resources/publishing-policies?tab=3.
[21] See for instance examples on the UNESCO website (UNESCO 2023); on the matter see also the end of the keynote lecture by Pierazzo (2024).
[22] OpenAI 2025, here: https://web.archive.org/web/20260311133649/https://help.openai.com/en/articles/8313359-is-chatgpt-biased.
References
AI HLEG. 2019 “Ethics Guidelines for Trustworthy AI.” https://web.archive.org/web/20260324125714/https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai.
Bericht: Dr. Wolfgang Eulenbeck und Dr. Andreas Paulus an Kurfürst August von Sachsen, 1576-05-09. In Der Reichstag zu Regensburg 1576: D. Berichte und Weisungen, edited by Josef Leeb, Christiane Neerfeld, Eva Ortlieb, Florian Zeilinger, Roman Bleier, Gabriele Haug-Moritz, Georg Vogeler. 2023. Graz. https://web.archive.org/web/20260320100933/https://gams.uni-graz.at/o:rta1576.edd1e7d24431/sdef:TEI/get?mode=lesetext.
Brockman, Greg, Ilya Sutskever, and OpenAI. 2015. “Introducing OpenAI.” https://web.archive.org/web/20241007222900/https://openai.com/blog/introducing-openai/.
Chen, Hailin, Fangkai Jiao, Xingxuan Li, Chengwei Qin, Mathieu Ravaut, Ruochen Zhao, Caiming Xiong, and Shafiq Joty. 2024. “ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?” arXiv. https://doi.org/10.48550/arXiv.2311.16989.
Chiang, Wei-Lin, Lianmin Zheng, Ying Sheng, Lisa Dunlap, Anastasios Angelopoulos, Christopher Chou, Tianle Li, and Siyuan Zhuang. 2024. “Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference.” arXiv. https://doi.org/10.48550/arXiv.2403.04132.
Chudleigh, Sarah. 2024. “Alles, was Sie über GPT wissen sollten.” https://web.archive.org/web/20250608124031/https://botpress.com/de/blog/everything-you-should-know-about-gpt-5.
Galka, Selina, and Georg Vogeler. 2026. “Annotating, projecting, and interpreting named entities in digital scholarly editions with LLMs.” International Journal of Digital Humanities. https://doi.org/10.1007/s42803-025-00114-8.
Joseph von Hammer-Purgstall an Bernhard von Jenisch [Wien], 20.2.1794. In Joseph von Hammer-Purgstall. Korrespondenz, edited by Walter Höflechner, Martina Scholger, Alexandra Wagner, Sabrina Strutz, and Elisabeth Steiner. 2025. Graz. http://hdl.handle.net/11471/559.20.1.
Höflechner, Walter, Martina Scholger, Alexandra Wagner, Sabrina Strutz, Elisabeth Steiner, eds. 2025. Joseph von Hammer-Purgstall. Korrespondenz. Graz. http://hdl.handle.net/11471/559.20.
Jankovic, Nikola. “TEI Scholar”. https://chatgpt.com/g/g-5yZrEY1A7-tei-scholar, last accessed 10.01.2026.
Leeb, Josef, Christiane Neerfeld, Eva Ortlieb, Florian Zeilinger, Roman Bleier, Gabriele Haug-Moritz, Georg Vogeler, eds. 2023. Der Reichstag zu Regensburg 1576. Graz. https://web.archive.org/web/20260316120750/https://gams.uni-graz.at/context:rta1576.
Merton-McCann, Alex. 2023. “How To Manage Your Privacy When Using ChatGPT or Other Generative AI.” https://web.archive.org/web/20240804100338/https://www.mcafee.com/blogs/internet-security/chatgpts-impact-on-privacy-and-how-to-protect-yourself/.
Miyagawa, So. “Lex 0 Converter”. https://chatgpt.com/g/g-kOuPR6Q7u-tei-lex-0-converter?ref=pluginsurf, last accessed 10.01.2026.
OpenAI. 2024 (v6). “GPT-4 Technical Report.” arXiv. https://arxiv.org/abs/2303.08774v6.
OpenAI. 2025. “OpenAI Help Center.” https://web.archive.org/web/20250628133335/https://help.openai.com/en/.
Ouyang, Shuyin, Jie M. Zhang, Mark Harman, and Meng Wang. 2023. “LLM is Like a Box of Chocolates: the Non-determinism of ChatGPT in Code Generation.” arXiv. https://doi.org/10.48550/arXiv.2308.02828.
PCMAG. 2023. “Google Translate vs. ChatGPT: Which One Is the Best Language Translator?”. PCMAG, June 10, 2023. https://web.archive.org/web/20230610132257/https://www.pcmag.com/news/google-translate-vs-chatgpt-which-one-is-the-best-language-translator.
Pierazzo, Elena. 2024. “From Digital to Computational Scholarly Editing: Are We Ready for ChatGPT?” YouTube video, posted 05.03.2024. https://www.youtube.com/watch?v=4_PtwZiWVz0, last accessed 10.01.2026.
Pollin, Christopher. 2024a. “teiCrafter.” https://web.archive.org/web/20250804030610/https://digedtnt.github.io/teiCrafter/.
Pollin, Christopher, Martina Scholger, Patrick Sahle, Georg Vogeler, Torsten Schaßan, Stefan Dumont, Franz Fischer, Ulrike Henny-Krahmer, Christiane Fritze, Torsten Roeder, and Alexander Czmiel. 2024. “Workshop Generative KI, LLMs und GPT bei digitalen Editionen.” DHd 2024 Quo Vadis DH (DHd2024), Passau, Deutschland. Zenodo. https://doi.org/10.5281/zenodo.10893761.
Pollin, Christopher. 2025. “Workshopreihe Angewandte Generative KI in den (digitalen) Geisteswissenschaften.” (v1.1.0) Zenodo. https://doi.org/10.5281/zenodo.10647754.
Pollin, Christopher, Franz Fischer, Patrick Sahle, Martina Scholger, and Georg Vogeler. 2025. “When it was 2024 – Generative AI in the Field of Digital Scholarly Editions.” Zeitschrift für digitale Geisteswissenschaften 10. https://doi.org/10.17175/2025_008.
Pollin, Christopher. 2026. “Promptotyping: Zwischen Vibe Coding, Vibe Research und Context Engineering.” L.I.S.A. Wissenschaftsportal Gerda Henkel Stiftung. Digitale Geschichte(n). https://web.archive.org/web/20260601000000*/https://lisa.gerda-henkel-stiftung.de/digitale_geschichte_pollin.
Pope, Niki. 2024. “What Is Trustworthy AI?” Nvidia Blog. https://web.archive.org/web/20260324125112/https://blogs.nvidia.com/blog/what-is-trustworthy-ai/.
Quillen, Sam. 2023. “How Many Languages Does ChatGPT Speak?” Medium, Apr 27, 2023. https://web.archive.org/web/20240712110304/https://sjquillen.medium.com/how-many-languages-does-chatgpt-speak-bf5cfc35a586a.
Ramlochan, Sunil. 2023. “Openness in Language Models: Open Source vs Open Weights vs Restricted Weights.” https://web.archive.org/web/20250314093343/https://promptengineering.org/llm-open-source-vs-open-weights-vs-restricted-weights/.
Rohde, Friederike, Josephin Wagner, Andreas Meyer, Philipp Reinhard, Marcus Voss, Ulrich Petschow, and Anne Mollen. 2024. “Broadening the perspective for sustainable artificial intelligence: sustainability criteria and indicators for Artificial Intelligence systems.” Current Opinion in Environmental Sustainability 66. https://doi.org/10.1016/j.cosust.2023.101411.
Saravia, Elvis. 2022ff. “Prompt Engineering Guide.” https://web.archive.org/web/20240316135941/https://github.com/dair-ai/Prompt-Engineering-Guide.
Scholger, Martina, Sabrina Strutz, and Christopher Pollin. 2024. “Empowering Text Encoding with Large Language Models: Benefits and Challenges.” https://doi.org/10.5281/zenodo.13969082.
Scholger, Walter. 2025. “Künstliche Intelligenz im Spannungsfeld von Innovation und Regulierung.” https://doi.org/10.5281/zenodo.15790422.
Sebastian, Ebin. 2023. “Beyond the Clicks: A Closer Look at ChatGPT’s User Interface Through Heuristic Lenses.” Medium (Nov 22, 2023). https://web.archive.org/web/20240712083258/https://medium.com/@ebinsk000/beyond-the-clicks-a-closer-look-at-chatgpts-user-interface-through-heuristic-lenses-dee5560f9316.
Stahl, Bernd Carsten, and Damian Eke. 2024. “The ethics of ChatGPT – Exploring the ethical issues of an emerging technology.” International Journal of Information Management 74. https://doi.org/10.1016/j.ijinfomgt.2023.102700.
Strutz, Sabrina, and Georg Vogeler. 2025. “Towards an Evaluation Framework for Assessing Large Language Models in Text Encoding.” ADHO Digital Humanities Conference 2025 (DH 2025). Zenodo. https://doi.org/10.5281/zenodo.16364518.
Strutz, Sabrina, and Martina Scholger. 2025. “Beyond Rule-Based Processing: LLM-Assisted TEI Encoding of Editorial Interventions in Historical Correspondence.” TEI Annual Conference and Members’ Meeting 2025, Jagielloninan University in Kraków. Zenodo. https://doi.org/10.5281/zenodo.17176474.
Strutz, Sabrina. forthcoming. “A Multi-Dimensional Evaluation Framework for Assessing LLM Performance in TEI Encoding.” Journal of Open Humanities Data.
Strutz, Sabrina, and Martina Scholger. 2026. “LLM-Assisted Metadata Extraction and Normalization for Historical Correspondence: A Multi-Stage Pipeline Approach.” DHd 2026 Nicht nur Text, nicht nur Daten (DHd 2026), Vienna. Zenodo. https://doi.org/10.5281/zenodo.18862770.
TEI Consortium (eds.) 2026: “Guidelines for Electronic Text Encoding and Interchange.” Version 4.11.0. https://tei-c.org/Vault/P5/4.11.0/doc/tei-p5-doc/en/html/.
UNESCO. 2023. “Artificial Intelligence: examples of ethical dilemmas”. https://web.archive.org/web/20240712082302/https://www.unesco.org/en/artificial-intelligence/recommendation-ethics/cases.
Wikipedia contributors. 2024. “ErnieBot.” https://web.archive.org/web/20240712104208/https://en.wikipedia.org/w/index.php?title=Ernie_Bot&oldid=1232272722.
Yang, Zeyi. 2023. “Chinese ChatGPT alternatives just got approved for the general public.” MIT Technology Review (Aug 30, 2023). https://web.archive.org/web/20240712104430/https://www.technologyreview.com/2023/08/30/1078714/chinese-chatgpt-ernie-government-approval/.
Figures
Fig. 1: Prompt instructions to convert a letter from Joseph von Hammer-Purgstall to Bernhard von Jenisch into TEI.
Fig. 2: XML/TEI encoding of a letter from Hammer-Purgstall to Jenisch generated by ChatGPT (GPT-4o).
Fig. 3: The letter to August von Sachsen encoded in TEI using ChatGPT (GPT-4o). The entire second paragraph was left out in order to fit the beginning and end on the picture.
Fig. 4: First result from ChatGPT trying to identify persons and places in the letter of 1576. Wrongly identified places are highlighted.
Fig. 5: Geoname references of the places generated by ChatGPT.