Deutsches Textarchiv, Berlin-Brandenburgische Akademie der Wissenschaften (ed.), 2017. http://www.deutschestextarchiv.de/ (Last Accessed: 16.08.2017). Reviewed by Dario Kampkaspar (Herzog August Bibliothek / Austrian Centre for Digital Humanities an der Österreichischen Akademie der Wissenschaften), dario.kampkaspar (at) oeaw.ac.at. ||
Abstract
Owing to its well documented TEI subset and highly accurate transcriptions usually based on the first edition of a text, the German Textarchive (= Deutsches Textarchiv, DTA) is currently one of the best corpora for historical German texts (1600-1900), albeit not necessarily the most extensive. To date (August 2017) it contains around 3260 works. The full texts of the corpus are enhanced by digital facsimiles and encoded with regard to their visual features (e.g. layout, fonts) as well as annotated linguistically (e.g. PoS-tagging). The search engine focuses on linguistic features and allows for searching both exact spellings as well as spelling variants of a word. Due to its goal of providing a corpus for historical linguistics and the underlying selection criteria of the collection, no further comments or variants in other editions of one work than the first print are given. Even though there are minor points of criticism, due to the quality of its textual sources and the accurate documentation the DTA can be seen as a point of reference for other corpora.
Einleitung
1Das Deutsche Textarchiv (DTA) entstand als Projekt an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) und wurde von 2007 bis 2016 von der Deutschen Forschungsgemeinschaft (DFG) unter der Leitung von Wolfgang Klein und Alexander Geyken gefördert. Mit derzeit (August 2017) über 620.000 Seiten aus mehr als 3.260 verschiedenen Werken aus der Zeit zwischen ca. 1600 und 19001 gehört das DTA zwar nicht zu den größten Textkorpora, doch dies ist gar nicht sein Anspruch. Die übergreifende Leitlinie wird dem Nutzer gleich auf der Startseite mitgeteilt:2 „Grundlage für ein Referenzkorpus der neuhochdeutschen Sprache“ oder, detaillierter, in den Leitlinien:3 „Ziel des Deutschen Textarchivs (DTA) ist die Erstellung eines disziplinenübergreifenden Volltextkorpus deutschsprachiger Texte“. In diesem Sinne geht es mehr um die Erreichung und Einhaltung einer verlässlichen Qualität der Texterfassung, insbesondere was die sprachlichen Eigenarten eines Textes angeht. Neben dieses ‚Kernkorpus‘ treten noch die sogenannten DTA-Erweiterungen.4 Hierbei handelt es sich um Texte, die teils unter anderen Gesichtspunkten ausgewählt und digitalisiert wurden (siehe Abschnitt zum DTA Erweiterungskorpus DTAE).
Das Kernkorpus
2Aus der Zielsetzung des Kernkorpus ergeben sich viele der Eigenschaften des Deutschen Textarchivs, allen voran der Umstand, dass bei der Textauswahl und -aufbereitung hauptsächlich linguistische Gesichtspunkte im Vordergrund standen. Die Werke im DTA wurden nicht nach thematischen Gesichtspunkten ausgewählt, sondern, dem Ziel des Korpus entsprechend, wurde auf eine ausgewogene Zusammenstellung nach Textgenres geachtet und auf eine historisch-kritische Kommentierung der Texte verzichtet. Zur bestmöglichen Dokumentation des Sprachstandes wird überwiegend die erste verfügbare Ausgabe wiedergegeben.
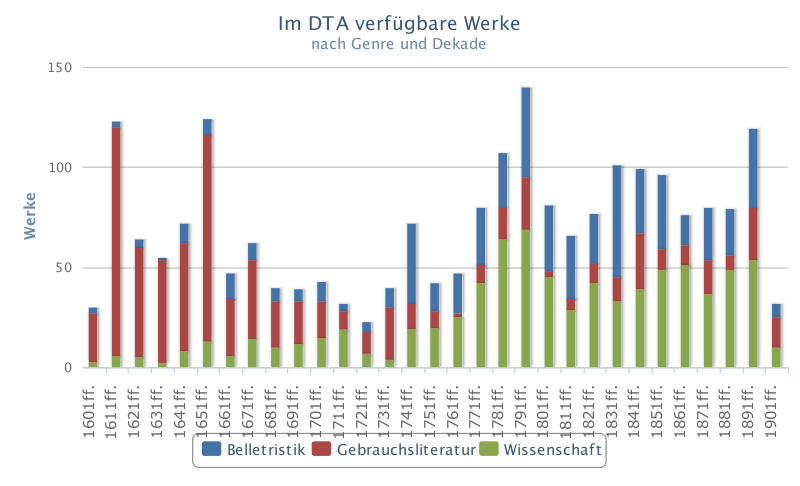
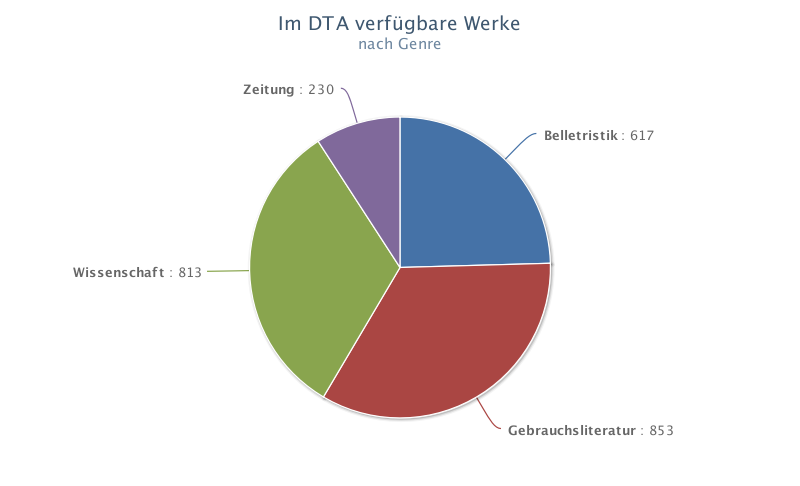
3Auch wenn der Anspruch einer ausgewogenen Textauswahl zur Abbildung des Neuhochdeutschen Sprachstandes und seiner Entwicklung nachvollziehbar ist, ist die Dokumentation, in der die Kriterien dieser Auswahl beschrieben werden,5 etwas dünn. So heißt es: Es wurden „mehrere Quellen herangezogen“, wobei „ausgewählte Literaturgeschichten“ und „Empfehlungen der Mitglieder der BBAW“ explizit genannt werden. Die Dokumentation der Textauswahl enthält zwei Graphiken: eine zur zeitlichen Verteilung der Werke (Fig. 1), die zur Zeit nur bedingt als gleichmäßig angesprochen werden kann, und eine zur Verteilung der Texte nach Genre (Fig. 2), wobei hier ‚Belletristik‘, ‚Gebrauchsliteratur‘, ‚Wissenschaft‘ und ‚Zeitung‘ genannt werden.6
4Scheint die Verteilung unter den ersten drei Gruppen noch recht gleichmäßig zu sein, stellt eine detailliertere Betrachtung7 ein etwas anderes Bild dar: So enthält die Gruppe ‚Belletristik‘8 beispielsweise eine Untergruppe ‚Briefe‘ mit mehreren Bänden Briefsammlungen9 (sowie einem Tagebuch!), während die Untergruppe ‚Novelle‘ deutlich mehr Werke verschiedener Personen umfasst (mit einem auffälligen Übergewicht auf den Werken Theodor Storms). Auch andere Untergruppen wie etwa ‚Lyrik; Prosa‘ zeigen, dass hier gegebenenfalls noch etwas Klassifizierungs- wie Aufteilungsarbeit geleistet werden könnte.
Texterfassung und Formate
5Das DTA versucht, bei den Texten des Kernkorpus eine möglichst hohe Erfassungsgenauigkeit zu erreichen. Neben der initialen Erfassung der Texte, die laut den Leitlinien in der Regel per Double Keying erfolgt, steht eine eigene browserbasierte Umgebung zur Qualitätskontrolle (DTA-Qualitätssicherung, DTAQ10) zur Verfügung. Über DTAQ können registrierte Benutzer Korrekturen und Annotationen am Text anbringen, die dann von Mitarbeitern des DTA geprüft und gegebenenfalls in die Texte eingearbeitet werden. Detailliert ausgearbeitete und sehr gut dokumentierte Regeln zur Transkription erlauben eine sehr verlässliche Auswertung der Texte, was auch durch das zugrunde gelegte Datenmodell unterstützt wird. Hierbei wurde basierend auf TEI P5 das DTA-Basisformat (DTA-Bf)11 erstellt, das ebenfalls vorbildlich dokumentiert ist. Dieses Format wurde dementsprechend auch von der DFG als Format für historische Texte empfohlen.12
6Der Fokus des Formates und der Erfassungsarbeit liegt auf der exakten Erfassung der Textstruktur sowie der originalen Schreibweisen und damit dem Aufbau eines Korpus historischer Wortformen. Für die weitergehende linguistische Bearbeitung wird auf das im Kontext von CLARIN-D entwickelte Text Corpus Format (TCF)13 zurückgegriffen.
7Wie bereits angesprochen kann die Dokumentation der Texterfassung und Modellierung des DTA in weiten Teilen als vorbildlich angesehen werden. Neben verschiedenen thematischen Zugängen (so zum Beispiel Metadaten und formale wie inhaltliche Erschließung) gibt es Übersichten zu den verwendeten Elementen und eine Suche innerhalb der Dokumentation. Da die Einhaltung dieser Regeln im Rahmen der Qualitätskontrolle DTAQ gesichert wird, sind die Texte des Kernkorpus in vielen Belangen der Goldstandard im Hinblick auf die weitere Verwendbarkeit. Ebenfalls positiv anzumerken ist, dass auch die Bestandteile der Dokumentation durch die Lizenz CC BY-SA 3.0 frei verfügbar sind.
Generelle Benutzerführung
8Der Zugriff auf die Texte ist auf mehreren Wegen möglich. Am auffälligsten ist dabei direkt auf der Startseite die Suchmöglichkeit, die bei einer Volltextsuche innerhalb des Korpus auch linguistische Verfeinerungen erlaubt.
9Als linguistische Suchengine wird DDC (‚Dialing/DWDS-Concordancer‘) verwendet, das umfangreiche linguistische Abfragen bietet. Unterstützt wird diese durch CAB (‚Cascaded Analysis Broker‘), ein Tool zur Findung moderner Wortformen zu historischen Schreibungen. Auch die (im Vergleich zu einfachen Volltextsuchen natürlich umfangreichere) Syntax der Engine ist mit Beispielen dokumentiert.14 Einige Features sind dabei die lexembasierte Suche (durch CAB gefundene Formen zu einem Grundlexem), Suche nach einer genauen Form mit oder ohne Trunkierung und die Suche von Phrasen (genaue Phrasen oder auch Wörter mit bestimmten Abständen zueinander) oder eine Suche aufgrund der Wortart. Diese Suchmöglichkeiten können für komplexe Anfragen miteinander kombiniert werden.
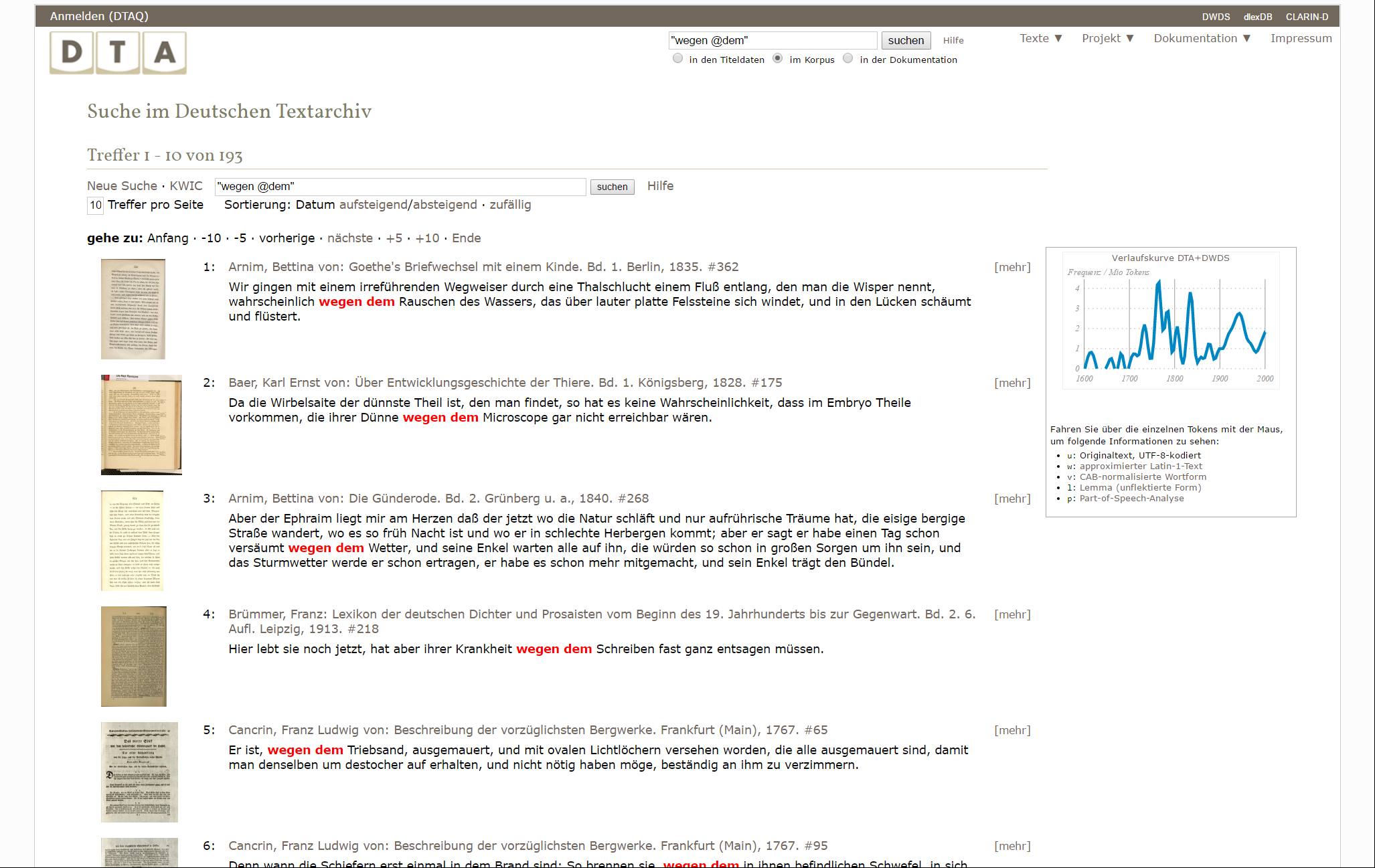
10In der Ergebnisansicht (Fig. 3) werden die Treffer im Kontext ihres Satzes angezeigt, wobei jeder Eintrag in der Liste einem Treffer entspricht (mehrere Treffer auf der gleichen Seite erzeugen standardmäßig jeweils eigene Einträge).15 Ebenfalls angeboten wird eine Verlaufskurve der gesuchten Form innerhalb des (gewählten Teil-)Korpus, wobei die Zahl der Treffer je einer Million Tokens über der Zeit angegeben wird. Ein Klick auf diese Graphik führt zu einer detaillierteren Ansicht.
11Neben der Volltextsuche gibt es in der Seitenspalte der Startseite die Möglichkeit zum ‚Stöbern im DTA‘, unter der alle Texte nach dem Jahrhundert der Veröffentlichung sowie nach der Textgattung (hier sehr weit gefasst in die drei Gruppen ‚Belletristik‘, ‚Gebrauchsliteratur‘ und ‚Wissenschaft‘; eine feinere Aufteilung erfolgt auf den jeweiligen Unterseiten) gruppiert werden. Dazu kommt im Menü ‚Texte‘ eine Zeitleiste, die die Titel nach ihrem Erscheinungsjahr zusammengefasst aufführt. Wer Werke eines bestimmten Verfassers sucht, muss entweder die Suche in den Titeldaten bemühen oder – weniger offensichtlich – in der Seitenspalte unter ‚Neue Werke im DTA‘ dem Link ‚alle Titel …‘ folgen.
Textansichten
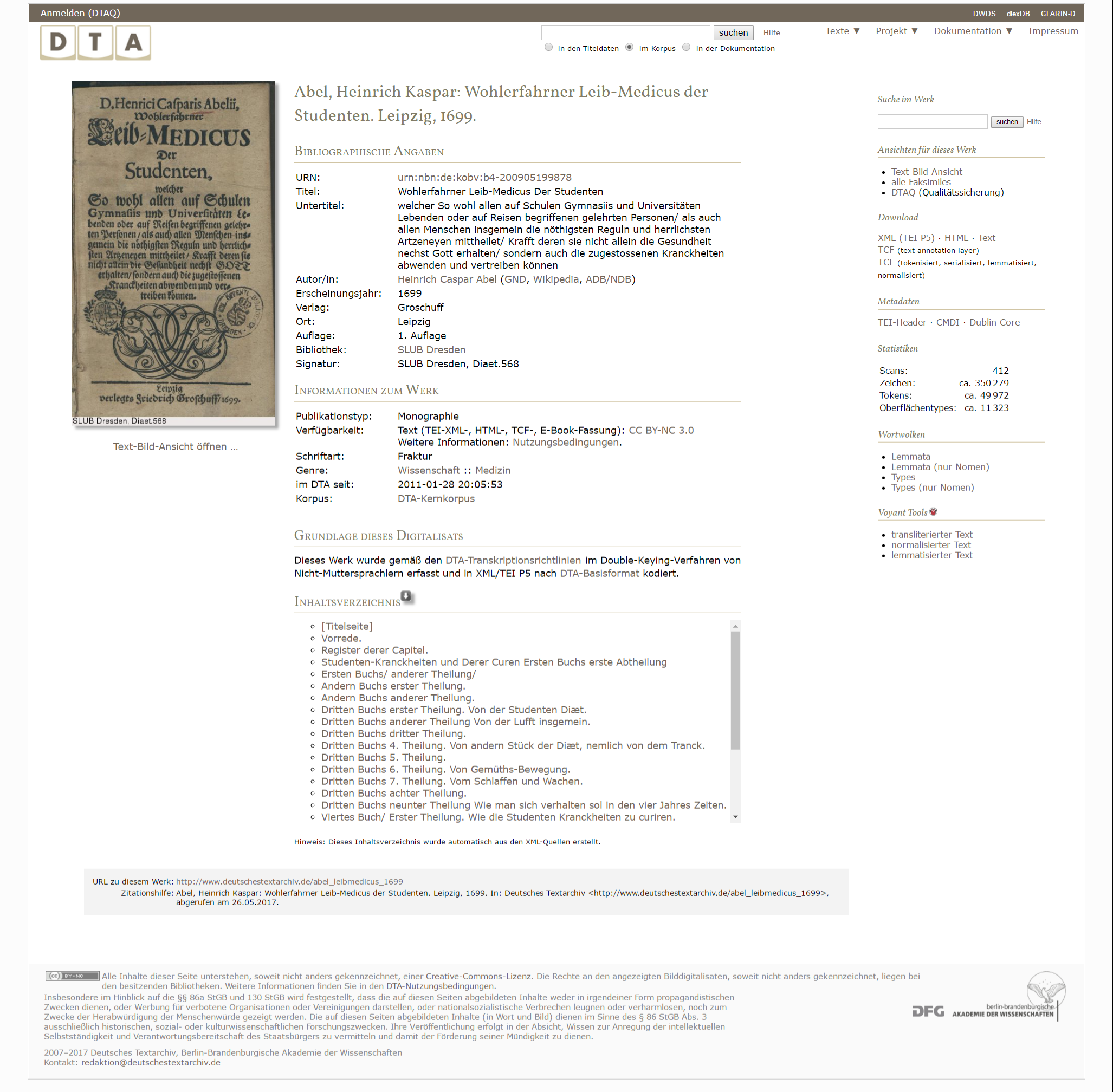
12Die Einstiegsseite eines Textes (Fig. 4) bietet bibliographische Angaben, weitere Metadaten, den Zugang zu den Ansichten des Textes, verschiedene Download-Optionen sowie Statistiken und Links zu einigen Tools (zur Zeit Wortwolken sowie die Übergabe des transliterierten, normalisierten oder lemmatisierten Textes an Voyant Tools). Die bibliographischen Angaben enthalten die üblichen Titelangaben, die URN des Textes zur permanenten Adressierung sowie Informationen zu dem für die Transkription verwendeten Exemplar. Die Metadaten sind neben anderen Formaten als TEI-Header und Dublin Core verfügbar, während für den Volltext verschiedene Versionen angeboten werden: erfasster Volltext als XML (im DTA-Bf), eine HTML-Ansicht, Plain Text, sowie linguistische Annotationen verschiedenen Umfanges als TCF. Die Download-Option ‚HTML‘ gibt zwar den gesamten Text als HTML wieder, bietet diesen aber tatsächlich zum Speichern an; den Volltext in einer einzigen HTML-Datei online einzusehen, scheint nicht vorgesehen zu sein.
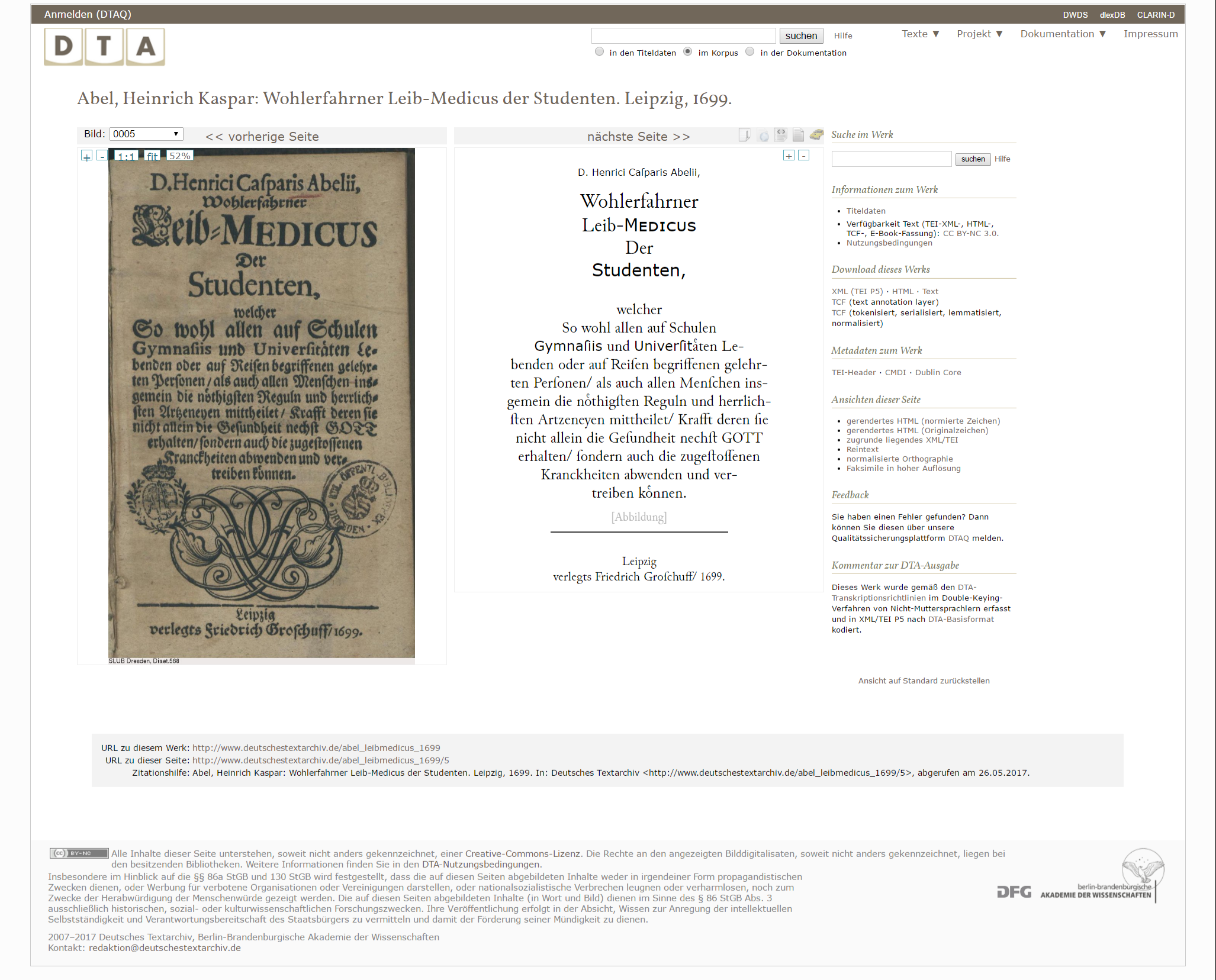
13Der Standard-Zugang zum Text ist die Text-Bild-Ansicht, die eine seitenweise Parallelansicht bietet (Fig. 5). Die auf der Einstiegsseite gebotenen Optionen sind hier (bei ausreichender Fensterbreite) am rechten Seitenrand zu finden. Die parallele Ansicht stellt Digitalisat und Transkription nebeneinander, wobei für die Transkription verschiedene Anzeigeformate gewählt werden können: das originale XML, eine HTML-Ansicht der getreuen Abschrift oder verschiedene Normalisierungen. Leider sind die Größen der Seitenbestandteile fix vorgegeben, sodass teils sogar bei kurzen Seiten innerhalb der Transkription gescrollt oder die Schriftgröße angepasst werden muss, um den gesamten Text einer einzelnen Textseite zu lesen. Die Informationen zum gesamten Werk sind auch hier jederzeit abrufbar und es werden außerdem der Link zum gesamten Werk, zur einzelnen Seite (nicht aber jeweiligen Ansicht) und eine Zitationshilfe mitgegeben. Verschiedene Versionen des Textes, der sich durch die Qualitätssicherung DTAQ ändern könnte, sind nicht abrufbar. Zwar ist durch die bereits vor der Veröffentlichung greifenden Kontrollmechanismen nicht von großen Änderungen auszugehen, doch ist gerade bei den oft feinfühligen linguistischen Suchen hier das Problem der fehlenden Nachvollziehbarkeit einer Aussage, die auf einem älteren Datenstand basiert, nicht von der Hand zu weisen. Bislang noch nicht umgesetzt, aber eine denkbare Erweiterung wären, sind Möglichkeiten zur Anbringung privater Annotationen oder Lesezeichen sowie Möglichkeiten zur Adressierung von Textauszügen, zum Beispiel unter Nutzung der Tokenisierung.
DTA Erweiterungskorpus (DTAE)
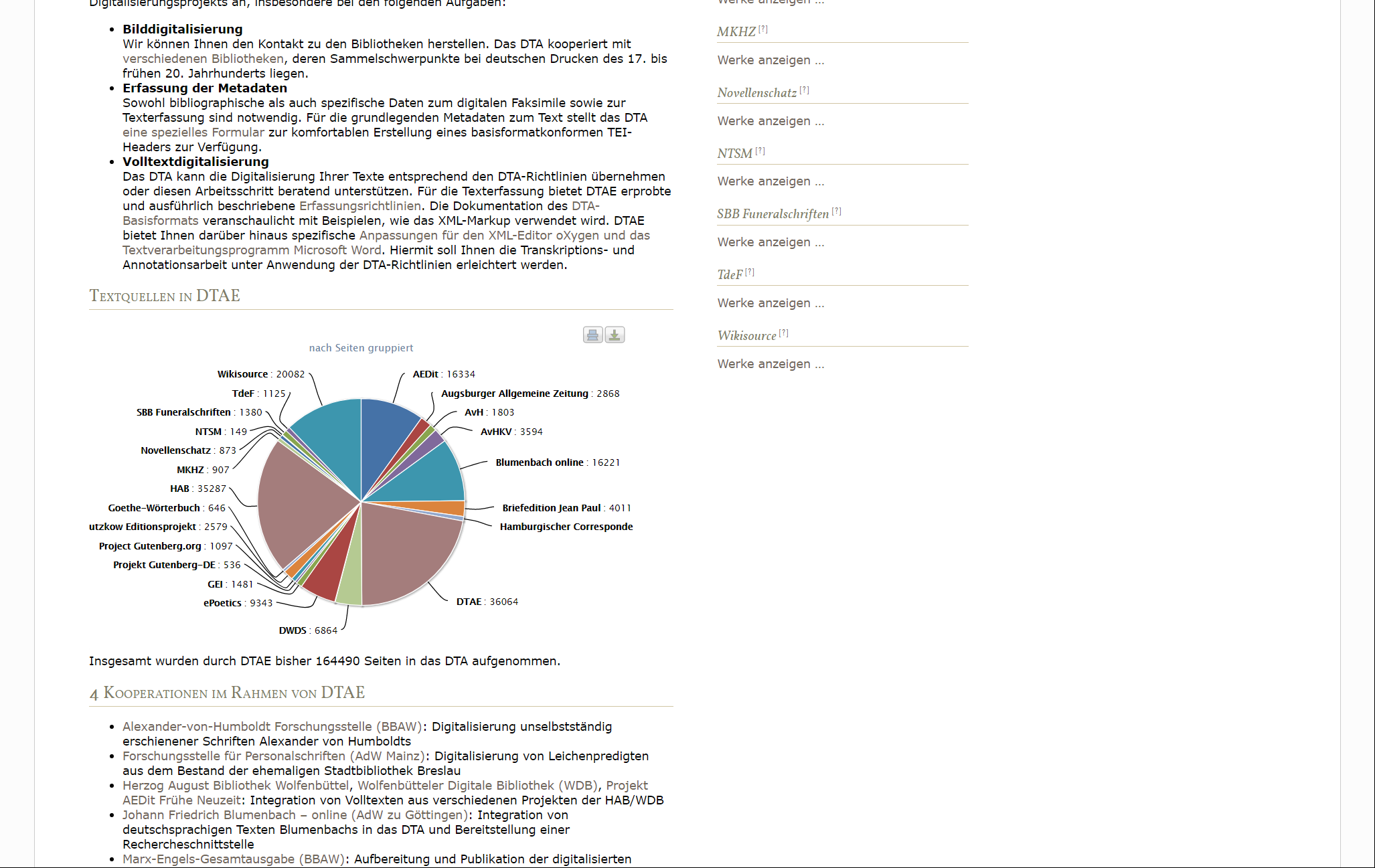
14Die derzeit (August 2017) knapp 165.000 Seiten im Erweiterungskorpus16 stammen aus externen Quellen, wobei es sich um Korpora einzelner Institutionen wie der Wolfenbütteler Digitalen Bibliothek (WDB), der Herzog August Bibliothek Wolfenbüttel (HAB), Kooperationsprojekte wie ‚AEDit‘ (HAB, BBAW und Akademie der Wissenschaften und Literatur in Mainz) oder Einzelprojekte wie ‚Semantic Blumenbach‘ an der Akademie der Wissenschaften in Göttingen handeln kann (Fig. 6). Ergänzt wird das DTAE durch weitere Volltexte, die aus digitalen Archiven (überwiegend Wikisource) übernommen und in das DTA-Bf überführt wurden.
15Ausführlichere Informationen zu den einzelnen Quellen der übernommenen Texte sind nicht auf derselben Seite zu finden – unter der Graphik sind nur kurze Informationen zu den Kooperationen aufgeführt –, sondern unter ,Textquellen‘ in der Dokumentation.17 Hier erst findet man die Erklärung, dass sich unter dem Beiträger ‚DTAE‘ (wie er in der Grafik in Fig. 6 auftritt) kein Zirkelschluss verbirgt, sondern eine Zusammenfassung kleinerer Einzelquellen ohne genaue Zuordnung zu einer Institution.
16In der rechten Spalte lässt sich auch eine Übersicht der Texte aufrufen, die aus den einzelnen Projekten übernommen sind. Eine Angabe, zu welchem Zeitpunkt und in welcher Form (Bilddigitalisat, Volltexte) Daten von einer Quelle übernommen wurde, sucht man hier wie auch in der Kurzbeschreibung vergebens. Die Liste enthält alle übernommenen Texte, auch wenn sie noch nicht kontrolliert wurden. Es ist nicht erkennbar, welche Links zu einem Volltext führen und welche zum DTAQ. Eine deutlichere Kennzeichnung wäre für den Benutzer hilfreich.
Zugänglichkeit und Nachnutzung
17Die Texte werden in der Regel unter verschiedenen freien Lizenzen zur Verfügung gestellt. Genauere Angaben lassen sich auf den jeweiligen Seiten einzelner Werke entnehmen. Die verschiedenen zur Verfügung gestellten Downloadformate und Lizenzen erlauben eine Weiterverwendung in verschiedenen Forschungskontexten.
18Als einfachste Variante der Übernahme ist ein Download des gesamten Korpus (nur Kernkorpus oder Kern- und Ergänzungskorpus) wie auch der einzelnen Gruppen, wie sie unter ‚Stöbern‘ zu finden sind, möglich. Eine Gruppierung der Texte durch den Nutzer ist zurzeit nicht umgesetzt. Es werden außerdem einzelne ‚Versionen‘ dieser Download-Optionen angeboten, wenngleich diese eher den Charakter von Snapshots mit schwankendem zeitlichen Abstand von teils fast zwei Jahren haben und so nur als grobe Versionierung der Texte dienen können.
19Die bei der Erstellung des Korpus verwendete Software wird im Rahmen der Dokumentation ebenfalls knapp beschrieben,18 wobei aber nicht immer klar ist, ob und inwiefern es sich um Eigenentwicklungen handelt. Teile der Software sind für die eigene Nutzung verfügbar, doch ist bei den externen Links oft nicht ersichtlich, in welchem Umfang und unter welcher Lizenz diese Software-Stücke genutzt werden können. Für die Verwendung im XML-Editor oXygen wird eine auf das DTA-Bf zugeschnittene Anpassung zur Verfügung gestellt, die mit einer Veröffentlichung im November 2013 aber auf einer nicht mehr aktuellen Version von oXygen basiert.
20Erfreulich ist das Angebot an APIs. Neben einer OAI-PMH Schnittstelle wird auch eine API zu CAB angeboten.19 Etwas dürftig ist allerdings die ‚Dokumentation‘ der APIs ausgefallen, beschränkt sie sich doch auf eine einfache Aufzählung von Links. Ohne weitere Unterscheidung stehen hier Atom-Feeds neben einem Link zur OAI-PMH-Schnittstelle oder einem OpenSearch-Wrapper für die oben beschriebene Suche. Ergänzende Informationen könnten an dieser Stelle hilfreich sein.
Abschließende Bemerkungen
21Das Deutsche Textarchiv bietet seinem Anspruch entsprechend qualitativ hochwertig aufbereitete Texte, die insbesondere, aber nicht nur für die linguistische Nachnutzung einen ausgezeichneten Standard bilden. Die Dokumentation vor allem des verwendeten Datenformates kann mit Fug und Recht als vorbildlich bezeichnet werden. Kleinere Eigenarten der Benutzerführung oder der zur Verfügung gestellten Ansichts-, Browsing- oder Downloadoptionen stellen keine gravierenden Probleme dar und werden vom Projektteam im Rahmen ihrer Möglichkeiten sicherlich auch angegangen werden.
22Es steht zu hoffen, dass auch in Zukunft das hohe Niveau der Textaufbereitung gehalten und das Textkorpus sukzessive weiter ausgebaut werden kann. Leider ist der Webseite nicht zu entnehmen, wie sich die weitere Zukunft des DTA gestalten wird, nachdem die Förderung durch die DFG 2016 ausgelaufen ist. Genauso fehlen Angaben, ob die Vorhaltung der Texte dauerhaft gesichert ist. Zwar ist davon auszugehen, dass ein solch prominentes Projekt einer Akademie nicht sang- und klanglos verschwinden wird, doch sollten nach Ablauf eines Projektes zumindest kurze Hinweise zu Fragen der Archivierung und langfristigen Verfügbarkeit gegeben und möglichst sichtbar platziert werden.
23Der weitere Ausbau des Korpus auch durch externe Kooperationspartner lässt hoffen, dass sich die Datengrundlage noch deutlich erweitern wird. Kleinere hier angeführte Wermutstropfen schmälern die Leistung nicht und werden durch das Projektteam sicher geprüft werden. Durch die Qualität der Texte, aber insbesondere auch durch die Dokumentation des DTA-Basisformates hat das DTA Vorbildcharakter für viele andere Projekte.
Anmerkungen
1. Die Angaben sind der auf der Startseite recht prominent platzierten Statistik entnommen, die einen guten Überblick über die laufende Arbeit am Korpus gibt.
2. DTA, Startseite: https://web.archive.org/web/20170830180801/http://deutschestextarchiv.de/
3. DTA, Leitlinien: https://web.archive.org/web/20170526105849/http://www.deutschestextarchiv.de/do…
4. DTA, DTAE: http://www.deutschestextarchiv.de/dtae
5. DTA, Dokumentation: https://web.archive.org/web/20170526085322/http://www.deutschestextarchiv.de/do…
6. ‚Zeitung‘ als ‚Genre‘ taucht allerdings in der gattungsorientierten Auswahl auf der Startseite nicht auf.
7. Eine Übersicht über die Texte der Gruppen ist allerdings von hier aus nicht möglich; sie kann stattdessen von der Startseite aus erreicht werden.
8. DTA, Genre Belletristik https://web.archive.org/web/20170526103123/http://www.deutschestextarchiv.de/li…
9. Unter anderem Bettina von Arnims ‚Goethes Briefwechsel‘, eher ein Briefroman als eine unverfäschte Briefsammlung, und Ludwig Börnes ‚Briefe aus Paris‘, die auf Basis der früheren Edition der BBAW wiedergegeben wurden.
10. DTA, DTAQ: http://www.deutschestextarchiv.de/dtaq
11. DTA, Basisformat: https://web.archive.org/web/20170526111458/http://www.deutschestextarchiv.de/do…
12. http://www.dfg.de/download/pdf/foerderung/grundlagen_dfg_foerderung/information… und http://www.dfg.de/download/pdf/foerderung/grundlagen_dfg_foerderung/information…
13. Weblicht, TCF-Format: http://weblicht.sfs.uni-tuebingen.de/weblichtwiki/index.php/The_TCF_Format
14. DTA, DDC-Suche: https://web.archive.org/web/20170526123024/http://www.deutschestextarchiv.de/do…
15. Nach der Dokumentation der Suche sollten die Ergebnisse „alphabetisch nach dem Titel der Werke, in dem die Ergebnisse gefunden wurden, sortiert“ werden (vgl. https://web.archive.org/web/20170821082531/http://www.deutschestextarchiv.de/do…). Die Kopfzeile einer einfachen Suche nennt eine Sortierung nach Datum. Ohne weitere Eingriffe scheint jedoch, wie im abgebildeten Beispiel zu sehen, keine dieser Aussagen korrekt zu sein. Über die auf der Seite gegebenen Links oder über Parameter in der Suche kann zumindest eine Sortierung nach Datum erzwungen werden, eine alphabetische Anordnung ließ sich im Test nicht erreichen.
16. DTA, DTAE: http://www.deutschestextarchiv.de/dtae
17. DTA, Textquellen: https://web.archive.org/web/20170526092945/http://www.deutschestextarchiv.de/do…
18. DTA, Software: https://web.archive.org/web/20170526122208/http://www.deutschestextarchiv.de/do…
19. DTA, Dokumentation der APIs: https://web.archive.org/web/20170529084103/http://www.deutschestextarchiv.de/api, API zu CAB im Detail: http://odo.dwds.de/~moocow/software/DTA-CAB/.
Bibliographie
- DTA: Deutsches Textarchiv. 2007-2017. Berlin-Brandenburgische Akademie der Wissenschaften. http://deutschestextarchiv.de/
